Introduction
In today’s digital age, online communication is essential in our everyday lives. Many of us find ourselves engaged in many online meetings and telephone conversations throughout the day. Due to the nature of our work in today’s world, some find themselves having calls or attending meetings in less-than-ideal environments such as cafes, parks, or even cars. One persistent issue during our virtual interactions is the prevalence of background noise emitted from the other end of the call. This interference can lead to significant misunderstandings and disruptions, impairing comprehension of the speaker’s intended messages.
To effectively address the problem of unwanted noise in online communication, an ideal solution would involve applying noise cancellation on each user’s end, specifically on the signal captured by their microphone. This technology would effectively eliminate background sounds for each respective speaker, enhancing intelligibility and maximizing the overall online communication experience. Unfortunately, this is not the case, and not everyone has noise cancellation software, meaning they may not sound clear. This is where the inbound noise cancellation comes into play.
When delving into the topic of noise cancellation, it’s not uncommon to see terms such as speech enhancement, noise reduction, noise suppression, and speech separation used in a similar context.
In this article, we will go over the inbound speech enhancement and the main challenges applying it to online communication. But first, let’s dive in and understand the buzz and the difference between the inbound and outbound streams in the terminology of speech enhancement.
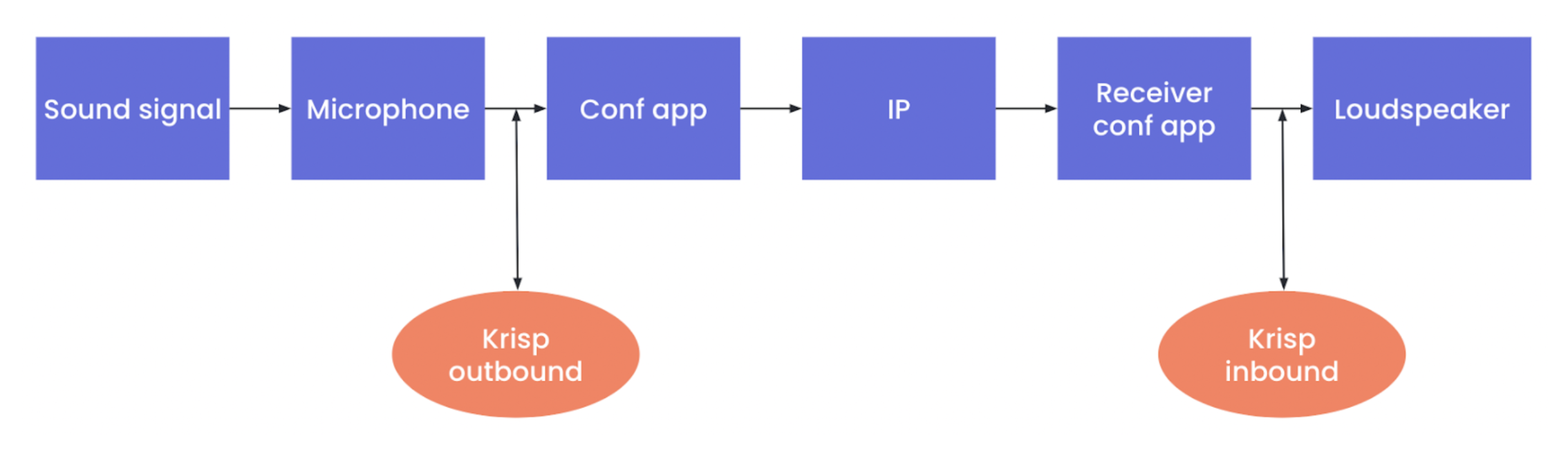
The difference in speech enhancement on the inbound and the outbound streams explained
The terms inbound and outbound we have referred to in the context of speech enhancement are basically about at which point in the communication pipeline the enhancement takes place.

Speech Enhancement On Outbound Streams
In the case of speech enhancement on the outbound stream, the algorithms are applied at the sending end after capturing the sound from the microphone but before transmitting the signal. In one of our previously published articles on Speech Enhancement, we focused mainly on the outbound use case.
Speech Enhancement On Inbound Streams
In the case of speech enhancement on the inbound stream, the algorithms are applied at the receiving end – after receiving the signal from the network but before passing it to the actual loudspeaker/headphone. Unlike outbound speech enhancement, which preserves the speaker’s voice, inbound speech enhancement has to preserve the voices of multiple speakers, all while canceling background noise.
Together, these technologies revolutionize online communication, delivering an unparalleled experience for users around the world.
The challenges of applying speech enhancement in online communication
Online communication is a diverse landscape, encompassing a wide array of scenarios, devices, and network conditions. As we strive to enhance the quality of audio in both outbound and inbound communication, we encounter several challenges that transcend these two realms.
Wide Range of Devices Support
Online communication takes place across an extensive spectrum of devices. The microphones in those devices range from built-in laptop microphones to high-end headphones, webcams with integrated microphones, and external microphone setups. Each of these microphones may have varying levels of quality and sensitivity. Ensuring that speech enhancement algorithms can adapt to and optimize audio quality across this device spectrum is a significant challenge. Moreover, the user experience should remain consistent regardless of the hardware in use.
Wide Range of Bandwidths Support
One critical aspect of audio quality is the signal bandwidth. Different devices and audio setups may capture and transmit audio at varying signal bandwidths. Some may capture a broad range of frequencies, while others may have limited bandwidth. Speech enhancement algorithms must be capable of processing audio signals across this spectrum efficiently. This includes preserving the essential components of the audio signal while adapting to the limitations or capabilities of the particular bandwidth, ensuring that audio quality remains as high as possible.
Strict CPU Limitations
Online communication is accessible to a broad audience, including individuals with low-end PCs or devices with limited processing power. Balancing the demand for advanced speech enhancement with these strict CPU limitations is a delicate task. Engineers must create algorithms that are both computationally efficient and capable of running smoothly on a range of hardware configurations.
Large Variety of Noises Support
Background noise in online communication can vary from simple constant noise, like the hum of an air conditioner, to complex and rapidly changing noises. Speech enhancement algorithms must be robust enough to identify and suppress a wide variety of noise sources effectively. This includes distinguishing between speech and non-speech sounds, as well as addressing challenges posed by non-stationary noises, such as music or babble noise.
The challenges specific to inbound speech enhancement
As we have discussed, Inbound speech enhancement may be a critical component of online communication, focusing on improving the quality of audio received by users. However, this task comes with its own set of intricate challenges that demand innovative solutions. Here, we delve into the unique challenges faced when enhancing incoming audio streams.
Multiple Speakers’ Overlapping Speech Support
One of the foremost challenges in inbound speech enhancement is dealing with multiple speakers whose voices overlap. In scenarios like group video calls or virtual meetings, participants may speak simultaneously, making it challenging to distinguish individual voices. Effective inbound speech enhancement algorithms must not only reduce background noise but also keep the overlapping speech untouched, ensuring that every participant’s voice is clear and discernible to the listener.
Diversity of Users’ Microphones
Online communication accommodates an extensive range of devices from different speakers. Users may connect via mobile phones, car audio systems, landline phones, or a multitude of other devices. Each of these devices can have distinct characteristics, microphone quality, and signal processing capabilities. Ensuring that inbound speech enhancement works seamlessly across this diverse array of devices is a complex challenge that requires robust adaptability and optimization.
Wide Variety of Audio Codecs Support
Audio codecs are used to compress and transmit audio data efficiently over the internet. However, different conferencing applications and devices may employ various audio codecs, each with its own compression techniques and quality levels. Inbound speech enhancement must be codec-agnostic, capable of processing audio streams regardless of the codec in use, to ensure consistently high audio quality for users.
Software Processing of Various Conferencing Applications Support
Online communication occurs through a multitude of conferencing applications, each with its unique software processing and audio transmission methods. Optimally, inbound speech enhancement should be engineered to seamlessly integrate with any of these diverse applications while maintaining an uncompromised level of audio quality. This requirement is independent of any audio processing technique utilized in the application. These processes can span a wide spectrum from automatic gain control to proprietary noise cancellation solutions, each potentially introducing different levels and types of audio degradation.
Internet Issues and Lost Packets Support
Internet connectivity is prone to disruptions, leading to variable network conditions and packet loss. Inbound speech enhancement faces the challenge of coping with these issues gracefully. The algorithm must be capable of maintaining the audio quality in case of lost audio packets. The ideal solution would even be able to mitigate the damage caused by poor networks by advanced Packet Loss Concealment algorithms.
How to face Inbound use case challenges?
As mentioned in the Speech Enhancement blog post, to create a high-quality speech enhancement model, one needs to apply deep learning methods. Moreover, in the case of inbound speech enhancement, we need to apply more diverse data augmentation reflecting real-life scenarios of inbound use cases to obtain high-quality training data for the deep learning model. Now, let’s delve into some data augmentations specific to inbound scenarios
Modeling of multiple speaker calls
In the quest for an effective solution to inbound speech enhancement, one crucial aspect is the modeling of multi-speaker and multi-noise scenarios. In an ideal approach, the system employs sophisticated audio augmentation techniques to generate audio mixes (see the previous article) that consist of multiple voice and noise sources. These sources are thoughtfully designed to simulate real-world scenarios, particularly those involving multiple speakers speaking concurrently, common in virtual meetings and webinars.
Through meticulous modeling, each audio source is imbued with distinct acoustic characteristics, capturing the essence of different environments and devices. These scenarios are carefully crafted to represent the challenges of online communication, where users encounter a dynamic soundscape. By training the system with these diverse multi-speaker and multi-noise mixes, it gains the capability to adeptly distinguish individual voices and suppress background noise.
Modeling of diverse acoustic conditions
Building inbound speech enhancement requires more than just understanding the mix of voices and noise; it also involves accurately representing the acoustic properties of different environments. In the suggested solution, this is achieved through Room Impulse Response (RIR) and Infinite Impulse Response (IIR) modeling.
RIR modeling involves applying filters to mimic the way sound reflects and propagates in a room environment. These filters capture the unique audio characteristics of different environments, from small meeting rooms to bustling cafes. Simultaneously, IIR filters are meticulously designed to match the specific characteristics of different microphones, replicating their distinct audio signatures. By applying these filters, the system ensures that audio enhancement remains realistic and adaptable across a wide range of settings, further elevating the inbound communication experience.
Versatility Through Codec Adaptability
An essential aspect of an ideal solution for inbound speech enhancement is versatility in codec support. In online communication, various conferencing applications employ a range of audio codecs for data compression and transmission. These codecs can vary significantly in terms of compression efficiency and audio quality, from enterprise-specific VOIP codecs like G.711 and G.729 to high-end solutions such as OPUS and SILK.
To offer an optimal experience, the solution should be codec-agnostic, capable of seamlessly processing audio streams regardless of the codec in use. To meet this goal, we need to pass raw audio signals to various audio codecs as the codec augmentation of training data.
Summary
Inbound speech enhancement refers to the software processing that occurs at the listener’s end in online communication. This task comes with several challenges, including handling multiple speakers in the same audio stream, adapting to diverse acoustic environments, and accommodating various devices and software preferences used by users. In this discussion, we explored a series of augmentations that can be integrated into a neural network training pipeline to address these challenges and offer an optimal solution.
Try next-level audio and voice technologies
Krisp licenses its SDKs to embed directly into applications and devices. Learn more about Krisp’s SDKs and begin your evaluation today.

References
- Speech Enhancement Review: Krisp Use Case. Krisp Engineering Blog
- Microphones. Wiley Telecom
- Bandwidth (signal processing). Wikipedia
- Babble Noise: Modeling, Analysis, and Applications. Nitish Krishnamurthy; John H. L. Hansen
- Audio codec. Wikipedia
- Deep Noise Suppression (DNS) Challenge: Datasets
- Can You Hear a Room?. Krisp Engineering Blog
- Infinite impulse response. Wikipedia
- Pulse code modulation (PCM) of voice frequencies. ITU-T Recommendations
- Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear prediction (CS-ACELP). ITU-T Recommendations
- Opus Interactive Audio Codec
- SILK codec(v1.0.9). Ploverlake
The article is written by:
- Ruben Hasratyan, MBA, BSc in Physics, Staff ML Engineer, Tech Lead
- Stepan Sargsyan, PhD in Mathematical Analysis, ML Architect, Tech Lead