Imagine you have an important online meeting, and there is a lot of noise around you. Kids are playing, the dog is barking, the washing machine is running, a fan is turned on, there is construction happening nearby, and you need to join a call. More often than not, it is nearly impossible to stop the noise or find a quiet place. In such situations, we need special audio processing technology that can remove background noises to improve the quality of online meetings.
This is one of the best applications of speech enhancement. Here we will discuss speech enhancement technology, give some historical background, review existing approaches, cover the challenges surrounding real-time communication, and explore how Krisp’s speech enhancement algorithm is an ideal solution.
First, let’s define Speech Enhancement (SE). It improves the quality of a noisy speech signal by reducing or removing background noises (see Figure 1). The main goal is to improve the perceptual quality and intelligibility of speech distorted by noise.
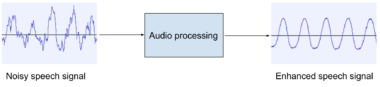
Figure 1. Speech enhancement.
We sometimes find other terms used interchangeably with speech enhancement, such as noise cancellation (NC), noise reduction, noise suppression, and speech separation.
There are lots of applications for speech enhancement algorithms, including:
- Voice communication, such as in conferencing apps, mobile phones, voice chats, and others. SE algorithms improve speech intelligibility for speakers in noisy environments, such as restaurants, offices, or crowded streets.
- Improving other types of audio processing algorithms by making them more noise-robust. For instance, we can apply speech enhancement prior to passing a signal to systems like speech recognition, speaker identification, speech emotion recognition, voice conversion, etc.
- Hearing aids. For those with hearing impairments, speech may be completely inaudible in noisy environments. Reducing noise increases intelligibility.
Traditional approaches
The first results of research centered around speech enhancement were obtained in the 1970s. Traditional approaches were based on statistical assumptions and mathematical modeling of the problem. Their solutions also depend largely on the application, noise types, acoustic conditions, signal-to-noise ratio, and the number of available microphones (channels). Let’s discuss them in more detail.
In general, we can divide speech enhancement algorithms into two types: multi-channel and single-channel (mono).
The multi-channel case involves two or more microphones (channels). In this case, the extra channel(s) contain information on the noise signal and can help to reduce the noise signal in the primary channel. An example of such a method is adaptive noise filtering.
This technique uses a reference signal from the auxiliary (secondary) microphone as an input to an adaptive digital filter, which estimates the noise in the primary signal and cancels it out (see Figure 2). Unlike a fixed filter, the adaptive filter automatically adjusts its impulse response. The adjustment is based on the error in the output. Therefore, with the proper adaptive algorithm, the filter can smoothly readjust itself under changing conditions to minimize the error. Examples of adaptive algorithms are least mean squares (LMS) and recursive least squares (RLS).
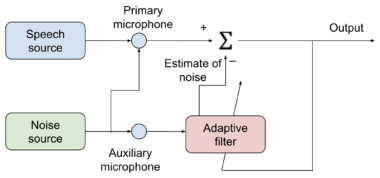
Figure 2. SE with adaptive noise filtering block diagram.
Another example of multi-channel speech enhancement is beamforming, which uses a microphone array to cancel out signals coming from directions other than the preferred source. Multi-channel speech enhancement can lead to promising results, but it requires several microphones and is technically difficult.
On the other hand, single-channel, or monaural speech enhancement, has a significant advantage because we don’t need to set up extra microphone(s). The algorithm takes input from only one microphone, which is a noisy audio signal representing a mixture of speech and noise, in order to remove unwanted noise.
The rest of the article is devoted to the monaural case.
One of the first results in the monaural case is the spectral subtraction method. There are various methods for this approach, but this is the idea behind the original method:
- Take the noisy input signal and apply a short-time Fourier transform (STFT) algorithm
- Estimate background noise by averaging the spectral magnitudes of audio segments (frames) without speech
- Subtract noise estimation from spectral magnitudes of noisy frames
- Then, by using the original phases of the noisy frame spectrums, apply an Inverse Short-time Fourier (ISTFT) transform to get an approximated signal of clean speech (see Figure 3).
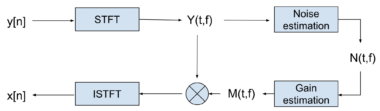
Figure 3: Spectral subtraction block diagram.
Another classical solution is the minimum mean-square error (MMSE) algorithm introduced by Ephraim and Malah.
With the rise of machine learning (ML), several solutions have also been proposed using ML-based traditional approaches such as Hidden Markov Models (HMM), non-negative matrix factorization (NMF), and wavelet transform.
To understand the limitations of these traditional approaches, note that we can divide noise signals into two categories: stationary and non-stationary. Stationary noises have a simpler structure. Their characteristics are mainly constant over time, such as fan noise, white noise, wind noise, and river sound. Non-stationary noises have time-varying characteristics and are more widespread in real-life. They include traffic noises, construction noises, keyboard typing, cafeteria sounds, crowd noises, babies crying, clapping, animal sounds, and more. The traditional algorithms can effectively suppress stationary noises, but they have little to no effect when suppressing more-challenging non-stationary noises.
Recent advances in computer hardware and ML have led to increased research and industrial applications of algorithms based on deep learning methods, such as artificial neural networks (NN). Starting in the 2010s, neural network algorithms made tremendous progress in natural language, image, and audio processing spheres. These systems outperform traditional approaches in terms of evaluation scores. 2015 saw the first results of speech enhancement via deep learning.
Deep learning approach
Figure 4 is a typical block diagram representing monaural speech enhancement using deep learning methods.
The goal is generally as follows:
Given an arbitrary noisy signal consisting of arbitrary noise and speech signals, create a deep learning model that will reduce or entirely remove the noise signal while preserving the speech signal without any audible distortion.
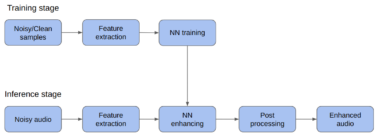
Figure 4: SE using deep learning, a block diagram.
Let’s go over the main steps of this approach.
- Training data: deep learning is a data-driven approach, so the end quality of the model greatly depends on the quality and amount of training data. In the case of speech enhancement, the raw training data is an audio set consisting of noisy and clean speech samples. To obtain such data we need to collect a clean speech dataset and a noise dataset. Then, by mixing clean speech and noise signals, we can artificially generate noisy/clean speech pairs as the model’s input/output data points. These are the most important aspects of data quality:
- A clean speech dataset should not contain any audible background noises
- Training voices and noises should be diverse to help the model generalize on unseen voices and noises
- It’s preferable that samples are from high-quality microphones because this gives more flexibility in data augmentations
2. Feature extraction: An example of reasonable feature extraction is an audio spectrogram or spectrogram-based features like Mel-frequency cepstral coefficients (MFCCs), which is a time and frequency representation of the signal that reflects the human auditory system’s response. As shown in Figure 5, we can visualize spectrograms as a color map of power spectrum values for time and frequency dimensions, where lighter colors mean higher values in Hz and vice versa.
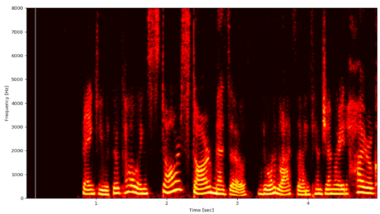
Figure 5: Example of speech spectrogram.
3. Neural Network: We can tune almost any type of neural network architecture for speech enhancement. We then treat spectrograms as images in order to use image processing techniques, such as convolutional networks. We can also represent audio as sequential data, meaning that recurrent neural networks can be a proper choice in that case. This is particularly true for gated recurrent units (GRU) and long short-term memory units (LSTM).
4. Training: During the training stage, the model “learns” generic patterns of clean speech spectrums and noise spectrums to distinguish between speech and noise. This ultimately enables it to recover the speech spectrum from the noisy/corrupted input.
After the training stage, we can use the model for inference. It takes noisy audio input, extracts features, passes it to the neural network, obtains the clean speech features, and, during post-processing, recovers the clean speech signal in the output. Studies show that speech enhancement models based on deep learning are superior to traditional approaches and show significant noise reduction, not only in the case of stationary noises but also in non-stationary ones.
Krisp Noise Cancellation
Each use case dictates the SE algorithm’s specific requirements. In the case of Krisp, our mission is to provide an on-device, real-time experience to users all over the world. That’s why the model works on small chunks of the audio signal without introducing any noticeable latency and has small enough FLOPs to consume a reasonable amount of computational resources. To achieve this goal, we use custom neural network architecture and digital signal processing algorithms in the pre and post-processing stages. Our training dataset includes several thousand hours of clean speech and noise. During the training stage, we also apply various data augmentations to cover microphone diversity, acoustic conditions, signal-to-noise ratios (SNR), bandwidths, and other factors.
We’ve achieved algorithmic latency of less than 20 ms, much less than the recommended maximum real-time latency of 200ms. Our evaluations and comparisons between our algorithms and other speech enhancement technologies show superior results, both in terms of the quality of preserved voice and the amount of eliminated noise.
Try next-level audio and voice technologies
Krisp licenses its SDKs to embed directly into applications and devices. Learn more about Krisp’s SDKs and begin your evaluation today.

This article was written by:
Dr. Stepan Sargsyan, PhD in Mathematical Analysis. Dr. Sargsyan is an ML Architect at Krisp.
References
[1] Lim, J. and Oppenheim, A. V. (1979), Enhancement and bandwidth compression of
noisy speech, Proc. IEEE, 67(12), 1586–1604.
[2] B. Widrow et al., “Adaptive noise cancelling: Principles and applications,” in Proceedings of the IEEE, vol. 63, no. 12, pp. 1692-1716
[3] S. Boll, “Suppression of acoustic noise in speech using spectral subtraction,” in IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 27, no. 2, pp. 113-120, April 1979
[4] Y. Ephraim and D. Malah, “Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator,” in IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 32, no. 6, pp. 1109-1121, December 1984
[5] M. E. Deisher and A. S. Spanias, “HMM-based speech enhancement using harmonic modeling,” 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, 1997, pp. 1175-1178 vol.2
[6] N. Mohammadiha, T. Gerkmann and A. Leijon, “A new approach for speech enhancement based on a constrained Nonnegative Matrix Factorization,” 2011 International Symposium on Intelligent Signal Processing and Communications Systems (ISPACS), 2011, pp. 1-5
[7] R. Patil, “Noise Reduction using Wavelet Transform and Singular Vector Decomposition”, Procedia Computer Science, vol. 54, 2015, pp 849-853,
[8] Y. Xu, J. Du, L. -R. Dai and C. -H. Lee, “A Regression Approach to Speech Enhancement Based on Deep Neural Networks,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 1, pp. 7-19, Jan. 2015
[9] Y. Zhao, B. Xu, R. Giri, and T. Zhang, “Perceptually guided speech enhancement using deep neural networks,” in 2018 IEEE Int. Conf. Acoustics Speech and Signal Processing Proc., 2018, pp. 5074-5078.
[10] T. Gao, J. Du, L. R. Dai, and C. H. Lee, “Densely connected progressive learning for LSTM-Based speech enhancement,” in 2018 IEEE Int. Conf. Acoustics Speech and Signal Processing Proc., 2018, pp. 5054-5058.
[11] S. R. Park and J. W. Lee, “A fully convolutional neural network for speech enhancement,” in Proc. Annu. Conf. Speech Communication Association Interspeech 2017.
[12] A. Pandey and D. Wang, “A new framework for CNN-Based speech enhancement in the time domain,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 27, July. 2019.
[13] F. G. Germain, Q. Chen, and V. Koltun, “Speech denoising with deep feature losses,” in Proc. Annu. Conf. Speech Communication Association Interspeech, 2019.
[14] D. Baby and S. Verhulst, “Sergan: Speech enhancement using relativistic generative adversarial networks with gradient penalty,” in 2019 IEEE Int. Conf. Acoustics, Speech and Signal Processing Proc., 2019.
[15] H. Phan et al., “Improving GANs for speech enhancement,” IEEE Signal Process. Lett., vol. 27, 2020.
[16] P. Karjol, M. A. Kumar, and P. K. Ghosh, “Speech enhancement using multiple deep neural networks,” in 2018 IEEE Int. Conf. Acoustics, Speech and Signal Processing Proc., 2018.
[17] H. Zhao, S. Zarar, I. Tashev, and C. -H. Lee, “Convolutional-Recurrent Neural Networks for Speech Enhancement,” 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 2401-2405.
[18] ITU-T G.114: https://www.itu.int/rec/T-REC-G.114-200305-I/en