We are inevitably going to have even more online meetings in the future. So it’s important to not get lost or lose context with all the information around us.
Just think about one of last week’s meetings. Can your team really recall everything discussed on a call??
When no one remembers exactly what was discussed during an online meeting, the effectiveness of these calls are reduced materially.
Many meeting leaders take hand-written notes to memorialize what was discussed to share and assign action items. However, the act of manually taking notes causes the note-taker to not be fully present during the call, and even the best note-takers miss key points and important dialogue.
Fixing meeting knowledge loss
In 1885, Hermann Ebbinghaus claimed that humans begin to lose recently acquired knowledge within hours of learning it. This means that you will recall the details of a conversation during the meeting, but, a day later, you’ll only remember about 60% of that information. The following day, this drops to 40% and keeps getting lower until you recall very little of the specifics of the discussion.
The solution?
Automatically transcribe meetings so that they can be reviewed and shared after the call. This approach helps us access important details discussed during a meeting, allowing for accurate and timely follow up and prevent misunderstandings or missed deadlines due to miscommunication.
Many studies have showed that people are generally more likely to comprehend and remember visual information as opposed to when they’re taking part in events/meetings that solely rely on audio for information sharing.
Meeting transcriptions provide participants with a visual format of any spoken content. It also allows attendees to listen and read along at the same time. This makes for increased focus during meetings or events, and improved outcomes post-meeting.
On-device processing
Having meeting transcript technology available to work seamlessly with all online meeting applications allows for unlimited transcriptions without having to utilize expensive cloud services.
At Krisp, we value privacy and keep the entire speech processing on-device, so no voice or audio is ever processed or stored in the cloud. This is very important from a security perspective, as all voice and transcripted data will be on-device under the users control.
It’s quite a big challenge to make transcription technologies work on-device due to constrained compute resources available vs cloud-based servers. Most transcription solutions are cloud-based and don’t deliver the accuracy and privacy of an on-device solution.. On-device technologies need to be optimized to operate smoothly, with specific attention to:
- Package size
- Memory footprint
- CPU usage (calculated using the real-time factor (RTF), which is the ratio of the technology response time to the meeting duration)
So every time we test a new underlying speech model, we first ensure that it is able to operate within the limited resources available on most desktop and laptop computers.
Technologies behind meeting transcripts
At first glance, it looks like the only technology behind having readable meeting transcriptions is simply converting audio into text.
But there are two main challenges with this simplistic approach:
- First, we don’t explicitly include punctuation when speaking like we do when writing. So we can only guess punctuation from the acoustic information. Studies have found that transcripts without punctuation are even more detrimental to understanding the information than a word error rate of 15 or 20%. So we need a separate solution for adding punctuation and capitalization to text.
- The second challenge is to distinguish between texts spoken by different people. This distinction improves the readability and understanding of the transcript. Differentiating between separate speakers is typically performed with a separate technology from core ASR, as there are hidden text-dependent acoustic features inside speech recognition models. In this case, text-independent speaker features are needed.
To summarize, meeting transcription technology consists of three different technologies:
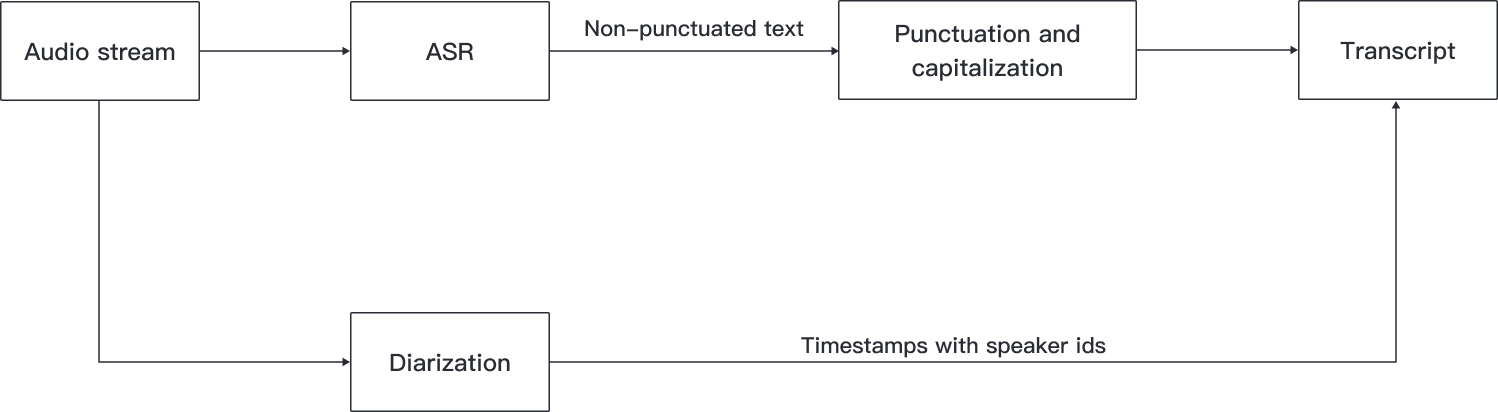
- ASR (Automatic Speech Recognition): Enables the recognition and translation of spoken language into text. Applying this technology on an input audio stream gives us lowercase text with only apostrophes as punctuation marks.
- Punctuation and capitalization of the text: Enables the addition of capitalization, periods, commas, and question marks.
- Speaker diarization: Enables the partitioning of an input audio stream into homogeneous segments according to every speaker’s identity.
The diagram below represents the process of generating meeting transcripts from an audio stream:

As mentioned above, all of these technologies should work on a device, even when the device is running on low CPU usage. For good results, a proper testing mechanism is needed for each of the models. Metrics and datasets are the key components of this type of testing methodology. Each of the models has further testing nuances that we’ll discuss below.
Datasets and benchmarks for speech recognition testing
To test our technologies, we use custom datasets along with publicly available datasets such as Earnings 21. This gives us a good comparison with both open source benchmarks and those provided through research papers.
For gathering the test data, we first define the use cases and collect data for each one. Let’s take online meetings as the main use case. Here we need conversational data for testing purposes. Moreover we need to consider that Plus, we’ll perform a competitor evaluation on the same data to see advantages and identify possible improvement areas for Krisp’s meeting transcription technology.
Testing the ASR model
Metrics
The main testing metric of the ASR model is the WER (Word Error Rate), which is being computed based on the reference labeled text and the processed one in the following way:

Datasets
After gathering custom conversational data for the main test, we augment it by adding:
- Noises at the signal-to-noise ratio (SNR) with dBs 0, 5, and 10.
- Reverberations with time from 100ms to 900ms.
- Low-pass and high-pass filters to simulate low-quality microphones.
- For this scenario, we’re also using the Earnings 21 dataset because its utterances have very low bandwidth
- Speech pace modifications.
We also want our ASR to support accents such as American, British, Canadian, Indian, Australian, etc.
We’ve collected data for each of those accents and calculated the WER, comparing the results with competitors.
Testing the punctuation and capitalization model
The main challenge of testing punctuation is the subjectivity factor. There can be multiple ways of rendering punctuation and all of them can be true. For instance, adding commas and even deciding on the length of a sentence depends on the grammar rules you want to use.
Metrics
The main metrics for measuring accuracy here are Precision, Recall, and the F1 score. These are calculated for each punctuation mark and capitalization instance.
- Precision: The number of true predictions of a mark divided by the total number of all predictions of the same mark.
- Recall: The number of true predictions of a mark divided by the total number of a mark.
- F1 score: The harmonic mean of precision and recall.
Datasets
Since we use the punctuation and capitalization model on top of ASR, we have to evaluate it on a text with errors. Taking this into account, we run our ASR algorithm on the meeting data we collected. Then, linguists manually punctuate and capitalize the output texts. Using these as labels, we’re ready to calculate the three above-mentioned metrics [Precision, Recall, F1 score].
Testing the speaker diarization model
Metrics
The main metrics of the speaker diarization model testing are:
- Diarization error rate (DER), which is the sum of the following error rates
- Speaker error: The percentage of scored time when a speaker ID is assigned to the wrong speaker. This type of error doesn’t account for speakers when the overlap isn’t detected or if errors from non-speech frames occur.
- False alarm speech: The percentage of scored time when a hypothesized speaker is labeled as non-speech.
- Missed speech: The percentage of scored time when a hypothesized non-speech segment corresponds to a reference speaker segment.
- Overlap speaker: The percentage of scored time when some of the multiple speakers in a segment don’t get assigned to any speaker.
- Word diarization error rate (see the Joint Speech Recognition and Speaker Diarization via Sequence Transduction paper), which calculates as:

Datasets
We used the same custom datasets as for the ASR models. We’ve made sure that the number of speakers varies a lot from sample to sample in this test data. Also, we performed the same augmentations like with ASR testing.
Conclusions on speech recognition testing
On-device meeting transcription combines three different technologies. All of them require extensive testing considering they should be hosted on a device.
The biggest challenges are choosing the right datasets and the right metrics for each use case as well as ensuring that all technologies run on the device without impacting other running processes.
Try next-level audio and voice technologies
Krisp licenses its SDKs to developers to embed directly into applications and devices. Learn more about Krisp’s SDKs and begin your evaluation today.

This article is written by:
Vazgen Mikayelyan, PhD in Mathematics | Machine Learning Architect, Tech Lead