Estimating the quality of speech is a central part of quality assurance in any system for generating or transforming speech.
Such systems include telecommunication networks or speech processing or generating software. The speech signal in their output suffers from various degradations inherent to the particular system.
With background noise cancellation, an algorithm could leave remnants of noise in an audio snippet or partially suppress speech (see Fig. 1). Or, a telecommunication system could also suffer from packet loss and delays. Meanwhile, audio codecs can introduce unwanted coloration just like speech-to-text systems deliver unnatural sounds.
A more straightforward approach to speech quality testing is conducting listening sessions, resulting in subjective quality results.
A group of people listens to recordings under controlled settings. They’re then asked to provide normalized feedback (e.g. on a scale from 1 to 5). Responses are then aggregated into a single quality value, called Mean Opinion Score (MOS).
Aggregation is necessary to avoid subject bias. There are standard guidelines for conducting such listening tests and for further statistical analysis of the results that yield the MOS values (see ITU-T P.830, ITU-R BS.1116, ITU-T P.835).
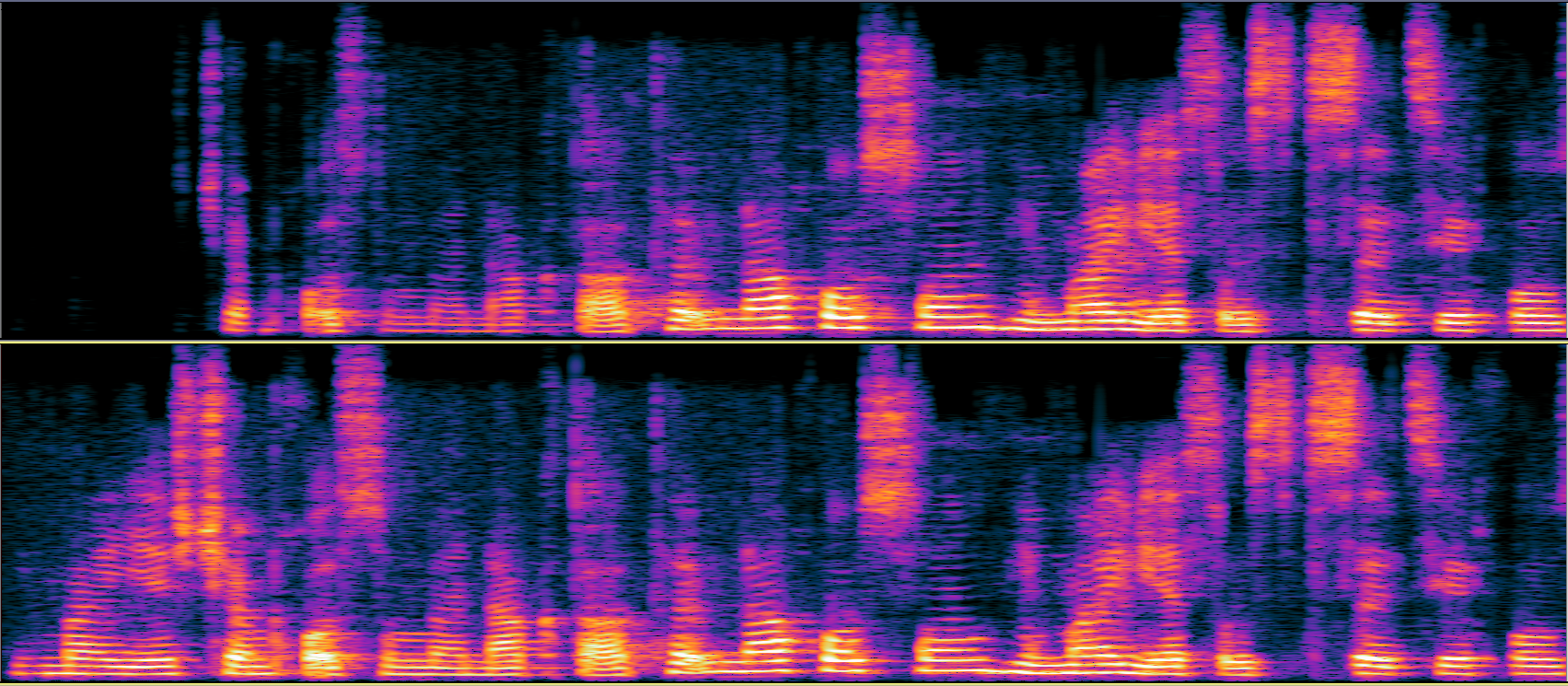
Fig. 1 An example of a degraded speech signal and its reference
In some circumstances, conducting listening sessions for collecting MOS is infeasible, laborious, or costly due to the large volume of the data to be tested.
This is where automated speech perceptual quality measures come into play. The aim is to replicate the way humans evaluate speech quality, avoiding subject bias inherent with subjective listening panels.
In short, the goal is to objectively approximate or predict voice quality in the presence of noise. The perceptual speech quality estimation is assessed in two cases, depending on whether clean reference speech can be compared with the system output or not (depicted in Fig. 2).
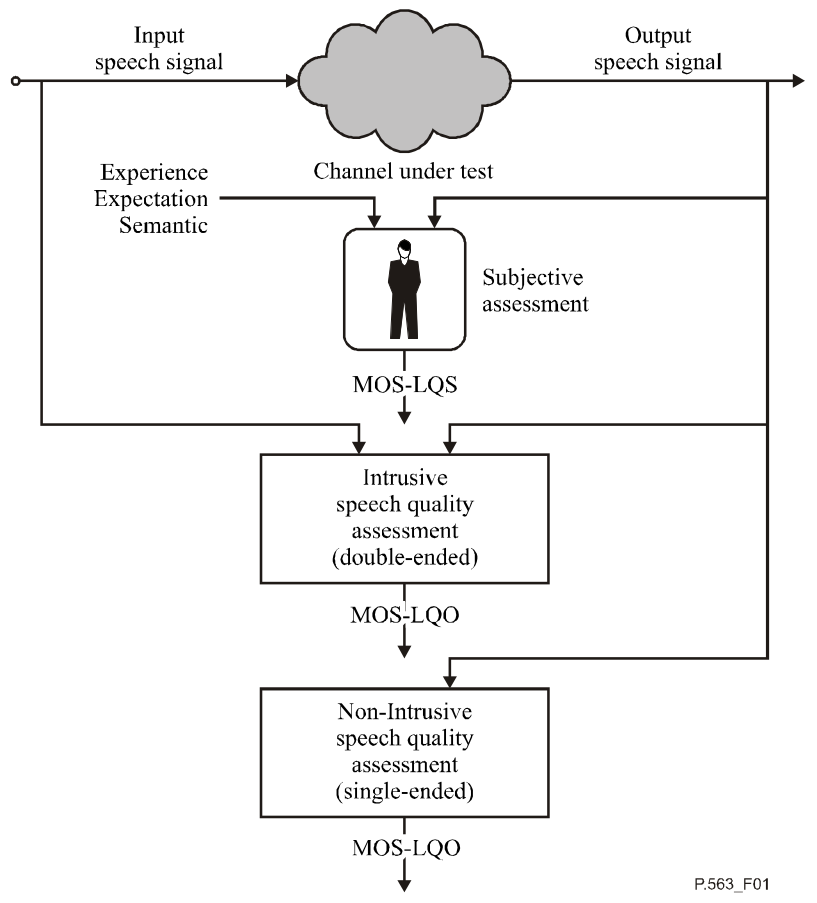
Fig. 2 Schematic view of intrusive and non-intrusive measures (source: ITU-T P.563)
Double-ended (intrusive) speech quality assessment measures
The model, in this case, has access to both the reference and output audio of the speech processing system. Its score is given based on the differences between the two. Please note that model and measure are used interchangeably in this article.
To mimic a human listener, automated methods should “catch” speech impairments that are detectable by the human ear/brain and assign them a quantitative value. It’s not enough to compute only mathematical differences between the audio samples (waveforms).
Such algorithms need to model the human psychoacoustic system. In particular, they’re expected to capture the ear functionality as well as certain cognitive effects.
To mimic human hearing capability, the model obtains an “internal” representation of the signals that mimics the transformations happening within the human ear. Signals of different frequencies are detected by separate areas of the cochlea (see Fig. 3). This “coverage” of frequencies isn’t linear. As a consequence, the audible spectrum can be partitioned into frequency bands of various widths the ear perceives as equal widths.
This phenomenon is modeled by psychoacoustic scales such as Bark and Mel scales (e.g. PESQ, NISQA double-ended, and PEAQ basic version), or by filter banks like the Gammatone filter bank (e.g. PEMO-Q, ViSQOL, PEAQ advanced version).
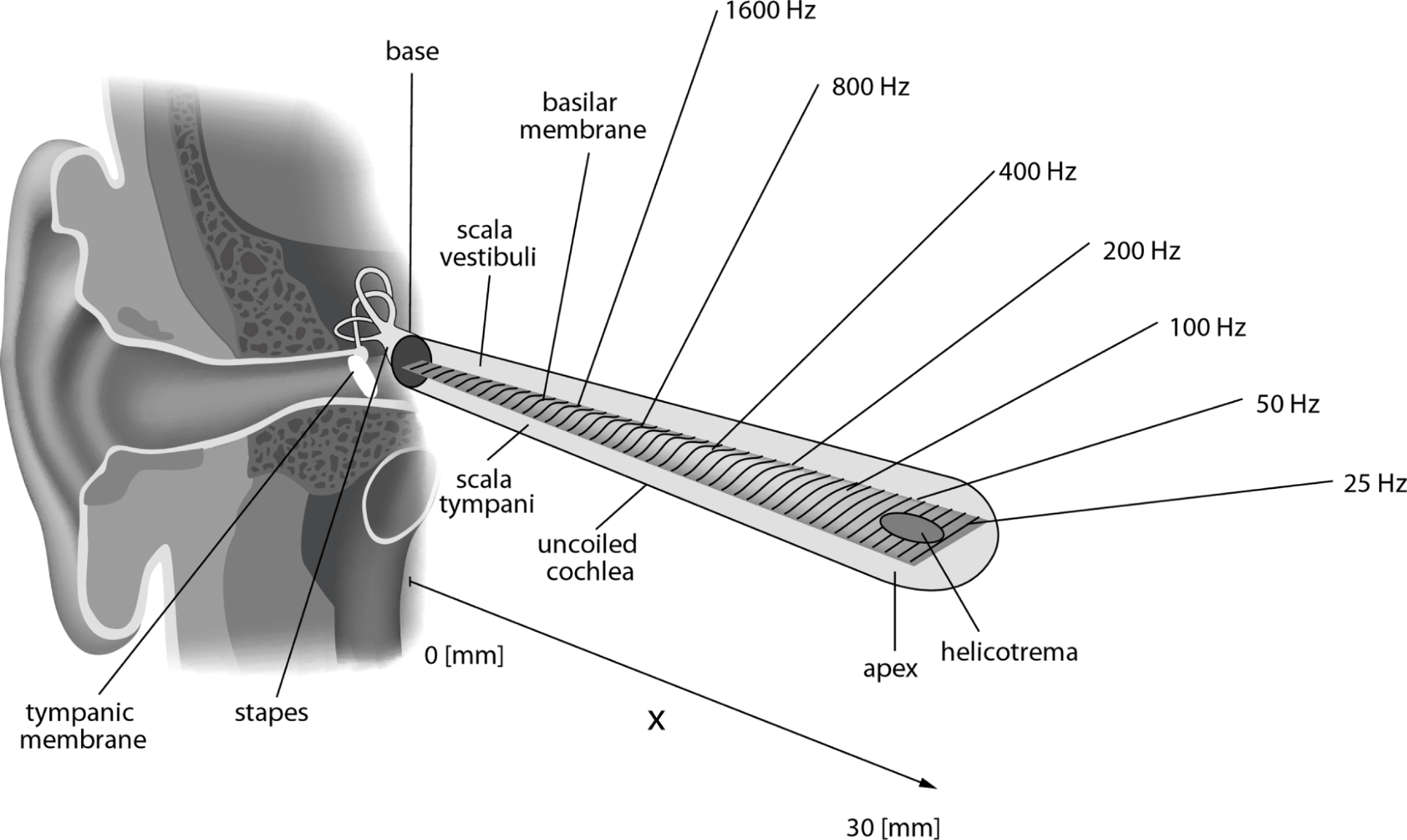
Fig. 3 Schematic view of auditory system (source)
Other voice quality aspects to consider are:
- The way loudness is perceived – this depends on the frequency structure of the sound, as well as its duration.
- The absolute hearing threshold – another time/frequency-dependent element, which can be between 2 and 3 kHz and is usually lower than that for other frequencies
- Masking effects – a loud sound may make a weaker sound inaudible when the latter occurs simultaneously or shortly after the former.
For audio quality testing in the case of telecommunication networks, it’s important to take into account missing signal fragments due to lost packets. Several models (e.g., PESQ, POLQA, NISQA) incorporate intricate alignment mechanisms that may take up the bulk of their computation.
Take PESQ alignment procedures as an example. These are based on signal cross-correlation between speech fragments while NISQA uses Attention networks for this.
Having computed an internal representation of reference speech and output signals, the model then works out the value of an appropriate function. The latter is designed to measure the difference between the two representations, mapping the result to a MOS value.
Quantifying the difference between internal representations is one of the main distinguishing factors of various quality measures. This may include further modeling of cognitive effects or resorting to pre-trained deep learning models (e.g. NISQA).
As an example, when evaluating loudness differences between signal fragments, PESQ gives higher penalty to missing fragments of speech than to additive noise. That’s due to the former being perceived as more disturbing to the listener.
Single-ended (non-intrusive) speech quality measures
In this case, the test algorithm only evaluates the output of the system without access to the reference speech. These metrics check if the given sound fragment is indeed human speech and whether it’s of good quality.
To achieve this, the way speech is produced by the human vocal tract should be modeled (see Fig. 4), along with the modeling of the auditory system. This appears to be a much more complex task than modeling the auditory system alone, as it involves more components and parameters. Additionally, the model needs to detect noise and missing speech fragments as well.
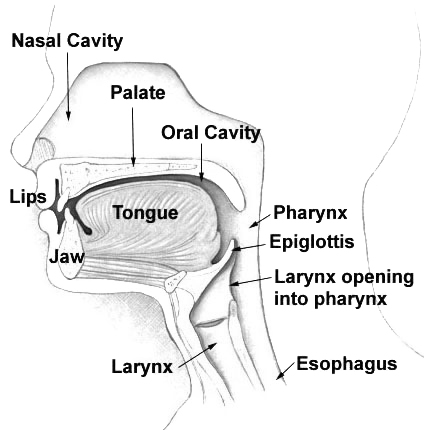
Fig. 4 Schematic view of human speech production system (source)
Some speech quality assessment methods do such modeling explicitly. For instance, the algorithm from the ITU-T P.563 standard estimates parameters of the human speech production system from a recording.
Using this, the algorithm generates a clean version of the reference speech signal. The result is then compared with the output signal using an intrusive quality measure like PESQ.
As mentioned earlier, such objective algorithmic models rely on a considerable number of hand-crafted parameters. This means this problem is a good candidate for machine learning methods.
There have been quite a few recent works approaching single-ended audio quality estimation using Deep Neural Nets (DNN) and other machine learning techniques. The DNN usually consists of a convolution-based feature extraction phase and a subsequent higher-level analysis phase where LSTM or Attention-based modules are used (e.g. NISQA, SESQA, MOSNet) or simply dense layers or pooling (e.g. CNN-ELM, WAWEnets). The result is then mapped to a MOS prediction value.
Another approach that’s been used with machine learning was, similar to ITU-T P.563, to synthesize a clean pseudo-reference version of the system output speech using machine learning (e.g. by using Gaussian Mixture Models to derive noise statistics from the noisy output of the system and compensate for the noise) and then compare it with the output speech using an intrusive method (see ref. 16).
Data generation for DNN models involves introducing speech degradations typical to the target use scenario. For example, applying various audio codecs to speech samples, mixing with noise, simulating packet loss and applying low/high-pass filters.
For supervised training, the training data needs to be annotated. The two main approaches here are either to annotate the data using known intrusive quality measures (e.g. SESQA, Quality-Net, WAWEnets) or conducting listening sessions for collecting MOS scores (MOSNet, NISQA, AutoMOS, CNN-ELM). In fact, models from the former group annotate the data using several intrusive measures, with the aim of smoothing out the shortcomings of particular measures.
Applicability for speech quality measures
Each speech quality measure was fitted to some limited data in the design stage and developed with usage scenarios and audio distortions in mind.
The specific application scenarios of perceived audio quality measures range considerably across different fields, such as telecommunication networks, VoIP, source speech separation or noise cancellation, speech-to-text algorithms, and audio codec design. This is true for both algorithmic and machine learning-based models, raising the question of cross-domain applicability of models.
From this point of view, DNN models crucially depend on the data distribution they’re trained on. On the other hand, algorithmic models are based on psychoacoustic research that doesn’t directly rely on any dataset.
The parameters of algorithmic measures are tuned to fit the measure output to MOS values of some dataset, but this dependence seems less crucial than for DNN models.
There are algorithmic measures that have been designed to be general quality measures, such as PEMO-Q. This phenomenon is well-reflected in a recent study (see ref. 18) that examines domain dependence of intrusive models with respect to audio coding and source separation domains. Among other things, they found out that standards like PESQ and PEAQ fare very well across these domains. This continues to happen although they weren’t designed for source separation. For PEAQ, one needs to take a re-weighted combination of only a subset of multiple output values to achieve good results.
Another aspect of usability is bandwidth dependence. This limitation is often specific to algorithmic measures.
While it’s rather easy to simulate audio instances of various bandwidths during data generation in DNNs, algorithmic models need explicit parameter tuning to give dependable outputs for different bandwidths. For example, the original ITU-T standard for PESQ was designed specifically for narrowband speech (then extended to support wideband), while its successor, POLQA, supports full-band speech.
A final consideration for speech and audio quality testing is performance. This may show up in massive and regular testing. DNN models can benefit from optimized batch processing, while multiprocessing can be applied with other measures.
Performance can be further improved if models were modular so that one could turn off certain functionality that isn’t necessary for a given application. For instance, we could improve the performance of the intrusive NISQA model in a noise cancellation application by removing its alignment layer (which isn’t necessary in this situation).
This was a short glimpse into the key points of objective speech quality measurement and prediction. This is an active research area with many facets that can’t be fully covered in a brief post. Please review the publications below for a more detailed description of signal to noise ratio measure and other speech quality assessment algorithms.
Try next-level voice and audio technologies
Krisp rigorously tests its voice technologies utilizing both objective and subjective methodologies. Krisp licenses its SDKs to developers to embed directly into applications and devices. Learn more about Krisp’s SDKs and begin your evaluation today.

The article is written by:
Tigran Tonoyan, PhD in Computer Science, Senior ML Engineer II
Aris Hovsepyan, BSc in Computer Science, ML Engineer II
Hovhannes Shmavonyan, PhD in Physics, Senior ML Engineer I
Hayk Aleksanyan, PhD in Mathematics, Principal ML Engineer, Tech Lead
References:
- ITU-T P.830: https://www.itu.int/rec/T-REC-P.830/en
- ITU-R BS.1116: https://www.itu.int/rec/R-REC-BS.1116
- ITU-T P.835: https://www.itu.int/rec/T-REC-P.835/en
- PESQ: ITU-T P.862, https://www.itu.int/rec/T-REC-P.862
- NISQA: G. Mittag et al., NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets, INTERSPEECH 2021 (see also the first author’s PhD thesis)
- PEAQ: ITU-R BS.1387, https://www.itu.int/rec/R-REC-BS.1387/en
- PEMO-Q: R. Huber and B. Kollmeier, PEMO-Q – A New Method for Objective Audio Quality Assessment Using a Model of Auditory Perception, IEEE Transactions on Audio, Speech, and Language Processing, 14 (6)
- ViSQOL: A. Hines et al., ViSQOL: The Virtual Speech Quality Objective Listener, IWAENC 2012
- ITU-T P.563: https://www.itu.int/rec/T-REC-P.563/en
- POLQA: ITU-T P.863, https://www.itu.int/rec/T-REC-P.863
- ANIQUE: D.-S. Kim, ANIQUE: an auditory model for single-ended speech quality estimation, IEEE Transactions on Speech and Audio Processing 13 (5)
- SESQA: J. Serrà et al., SESQA: Semi-Supervised Learning for Speech Quality Assessment, ICASSP 2021
- MOSNet: C.-C. Lo et al., MOSNet: Deep Learning-Based Objective Assessment, INTERSPEECH 2019
- CNN-ELM: H. Gamper et al., Intrusive and Non-Intrusive Perceptual Speech Quality Assessment Using a Convolutional Neural Network, WASPAA 2019
- WAWEnets: A. Catellier and S. Voran, Wawenets: A No-Reference Convolutional Waveform-Based Approach to Estimating Narrowband and Wideband Speech Quality, ICASSP 2020
- Y. Shan et al., Non-intrusive Speech Quality Assessment Using Deep Belief Network and Backpropagation Neural Network, ISCSLP 2018
- Quality-Net: S. Fu et al., Quality-Net: An end-to-end non-intrusive speech quality assessment model based on BLSTM, INTERSPEECH 2018
- M. Torcoli et al., Objective Measures of Perceptual Audio Quality Reviewed: An Evaluation of Their Application Domain Dependence, IEEE/ACM Transactions on Audio, Speech, and Language Processing 29
- ETSI standard EG 202 396-3: https://www.etsi.org