

Turn-Taking is a big challenge
AI Voice Agents are rapidly evolving, powering critical use-cases such as customer support automation, virtual assistants, gaming, and remote collaboration platforms. For these voice-driven interactions to feel natural and practical, the underlying audio pipeline must be resilient to noise, responsive, and accurate—especially in real-time scenarios.
In a typical deployment, audio streams originate from diverse endpoints like mobile applications, web browsers, or traditional telephony and are delivered via real-time communication protocols like WebRTC or WebSockets (WSS). This audio is aggregated and managed through specialized providers like LiveKit, Daily, or Agora, which ensure reliable, low-latency audio transport to the server-side pipeline.
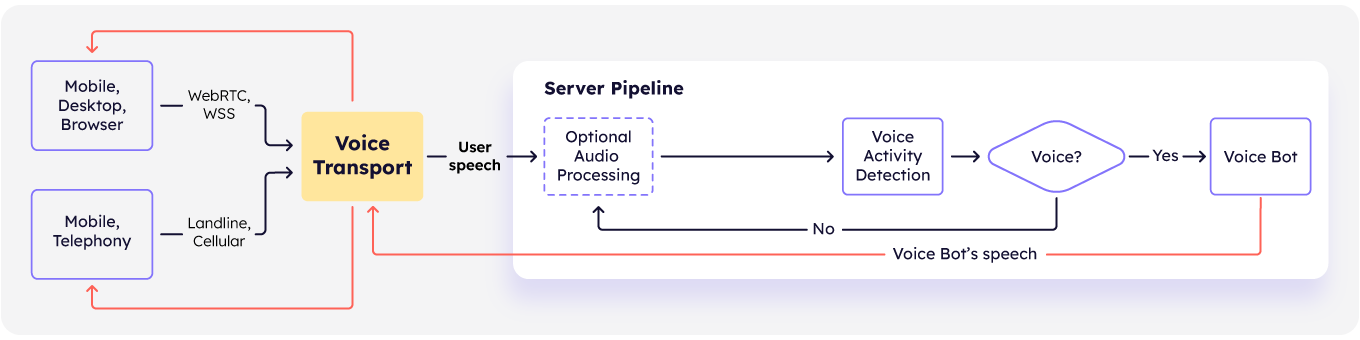
Within the server pipeline, once the audio arrives, it undergoes optional preprocessing steps for formatting or basic adjustments, after which it moves directly into a Voice Activity Detection (VAD).
VAD identifies active speech segments, driving automatic end-pointing and intelligent interruption handling. Following a user speech, when VAD detects silence, relevant API events trigger downstream Voice AI models to generate and deliver responses. If the user resumes speaking during the voice bot’s response generation, the pipeline seamlessly cancels the ongoing output and clears buffers, ensuring natural conversational turn-taking.
In this scenario, background noises—such as music, traffic sounds, TVs, or nearby conversations—remain embedded within the audio stream, reaching the VAD module unfiltered. Because VAD is designed to detect human speech activity, these background sounds often cause false-positive speech detections. As a result, the VAD mistakenly interprets noise or background voices as active user speech, triggering unintended interruptions. These false triggers negatively impact turn-taking, a core component of natural, human-like conversational interactions.
Here, by placing Krisp Background Voice and Noise Cancellation before the VAD, the pipeline substantially reduces false-positive triggers and prevents interruptions from common background distractions.
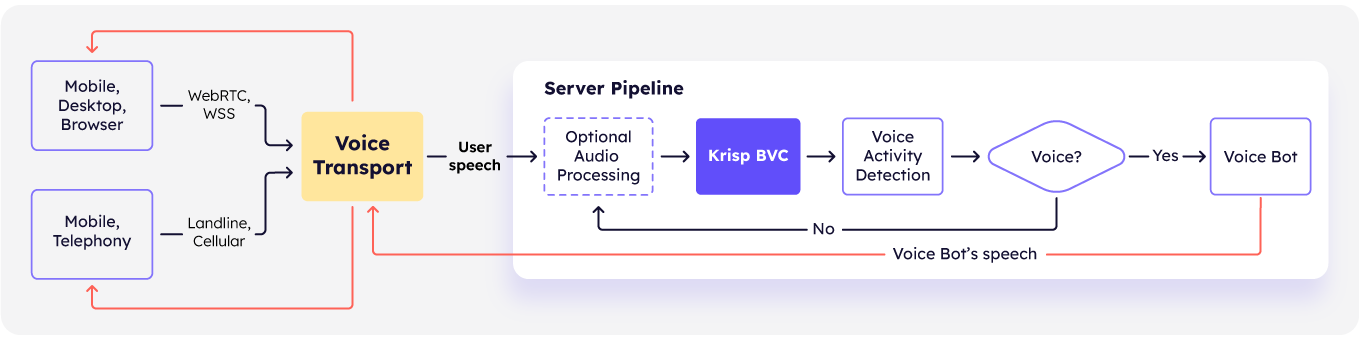
Additionally, Krisp significantly improves downstream speech processing accuracy by delivering cleaner audio.
Introducing Krisp Server SDK for AI Voice Agents
We’re excited to announce the launch of Krisp Server SDK, featuring two advanced AI models engineered explicitly for superior noise cancellation for AI Voice Agents.
Compared to our on-device AI models, these models are optimized to deliver unmatched performance and voice quality, especially in challenging corner cases.
Both models remove background noise, chatter, and secondary voices, ensuring the retention and clarity of only the primary speaker’s voice.
- BVC-tel (General-Purpose Model):
- Designed as a robust, versatile solution ideal for a wide variety of audio sources, including WebRTC, mobile, and traditional telephony inputs.
- Specifically engineered to be highly resilient against audio artifacts introduced by common telephony codecs, such as the G711 codec, widely used in telecommunication networks.
- Supports audio sampling rates up to 16 kHz, which is optimal for AI Voice Agents as it effectively captures the essential frequency ranges of human speech.
- BVC-app (High-Fidelity Model):
- Specifically optimized for WebRTC use-cases where high-quality audio streams are required.
- Supports higher sampling rates up to 32 kHz, enabling clearer, more natural-sounding voice interactions suitable for applications with superior audio fidelity.
ℹ️ If the incoming audio source has a sampling rate higher than the model’s supported rate (e.g., 48 kHz), the SDK intelligently manages the audio processing by automatically downsampling to the model’s working rate, applying the noise cancellation and then seamlessly upsampling back to the original audio quality.
Despite significant quality enhancements, server-side models maintain a low algorithmic latency of just 15 milliseconds, identical to our on-device models. This ensures real-time responsiveness, which is critical for conversational interactions.
The new Krisp Server SDK models are CPU-optimized and support a range of platforms, including:
- Linux (x64 and ARM64 architectures)
- Windows (x64) with ARM64 support coming soon.
Quantifying the Krisp BVC Impact
We comprehensively evaluated how the new Background Voice and Noise Cancellation (BVC) model improves turn-taking accuracy and speech recognition quality.
Using the BVC-tel model, we specifically tested two distinct audio pipeline scenarios:
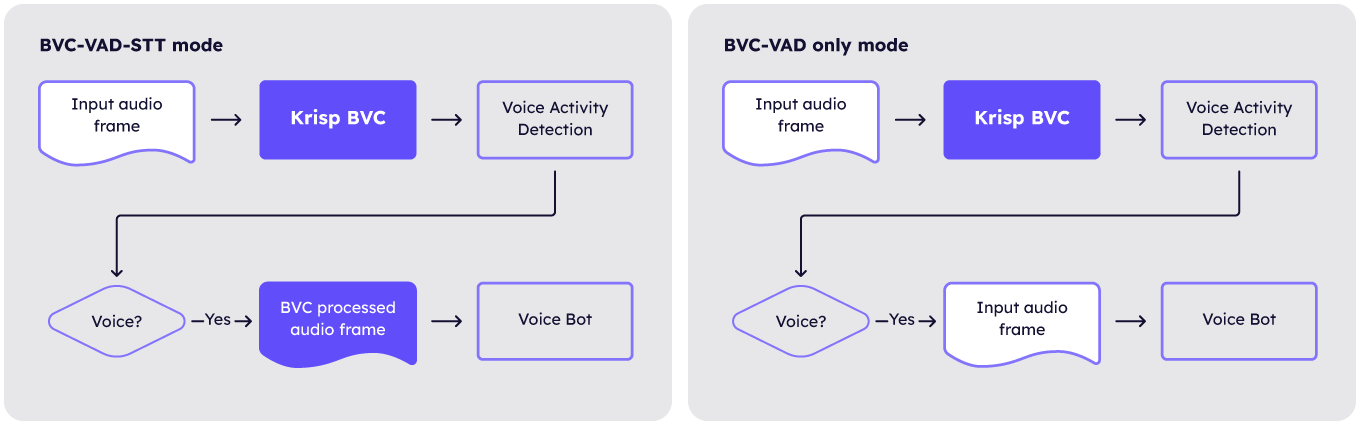
- BVC-VAD-STT: Audio processed by Krisp BVC and VAD is passed to the AI Voice Agent.
- BVC-VAD only: The original (unprocessed) audio is passed downstream to the AI Voice Agent, with Krisp BVC processed audio used solely for improved VAD accuracy.
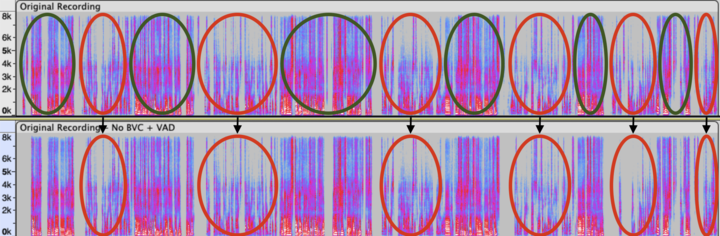
The following graphics and audio examples demonstrate a typical example: Krisp BVC effectively canceling the background TV speech when interacting with the AI Voice Agent.
The red-circled areas represent the TV speech. The green-circled areas represent the primary speaker’s speech.
Turn-taking with VAD only |
Turn-taking with BVC-VAD |
|---|---|
| TV speech passes through VAD, potentially interrupting the AI Voice Agent during its response. | TV speech passes through VAD, potentially interrupting the AI Voice Agent during its response. |
 |
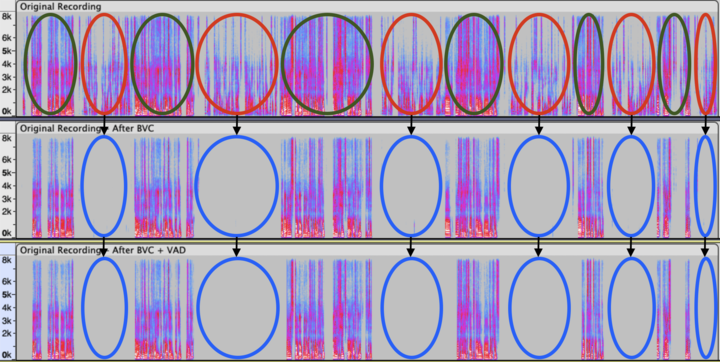 |
| Original Audio |
Original Audio |
| Audio after VAD processing only |
Audio after BVC processing |
| Audio after BVC + VAD processing |
In the following sections, we perform more comprehensive evaluations to capture and quantify improvements in turn-taking and WER improvements in STT.
Evaluation Setup:
- Dataset: We selected the widely-used AMI corpus, specifically the individual headset recordings. This dataset is ideal due to its realistic mix of background conversations and noise, which is representative of many typical mobile and telephony scenarios.
- Voice Activity Detection: Latest version of open-source SileroVAD
- Speech-To-Text Models: Whisper V3 (base version). In our tests, the difference between the base and large versions was insignificant, so we present only the base model results.
Impact on Turn-Taking
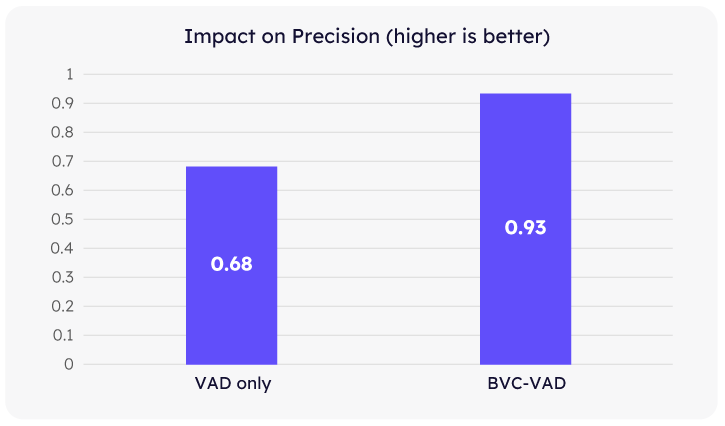
Applying Krisp BVC upstream had a clear, positive impact on VAD precision within the AMI dataset—especially in reducing false-positive speech detections. Lower false positives are particularly critical for ensuring smooth, uninterrupted conversational experiences.
 |
 |
|---|
Our tests show that with Krisp BVC, false-positive triggers in VAD were reduced by 3.5x on average. This means the AI Voice Agent is significantly less likely to experience unintended interruptions caused by background speech or noise. Overall, the precision after Krisp BVC increases by over a quarter—a major improvement.
Impact on Speech Recognition Accuracy (WER)
Using Krisp BVC also markedly reduces the Word Error Rate (WER) of Whisper V3 models on the AMI dataset—achieving more than a 2x improvement. This result aligns with expectations, given Krisp’s effectiveness in eliminating distracting background speech.
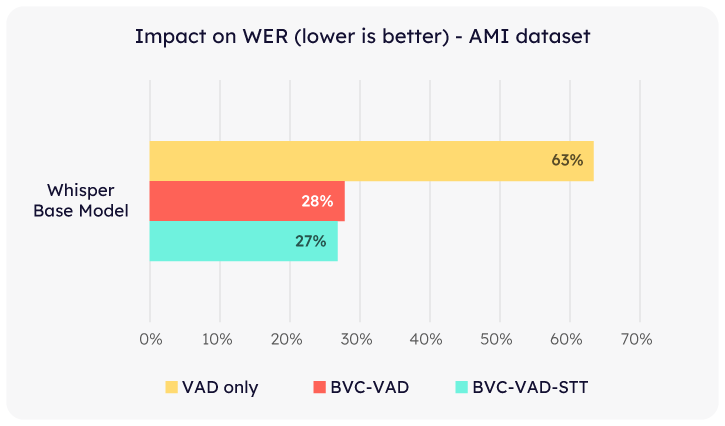
Interestingly, the WER improvements were consistent in both BVC-VAD and BVC-VAD-STT modes.
To further explore this, we evaluated an additional dataset with minimal background speech: the ITU-T P.501 dataset, which mixes single-speaker audio with 24 different noise types at three intensity levels (0db, 5db, 10db).
Modern STT models, including Whisper, generally have strong built-in noise robustness. We aimed to measure any further WER improvements achievable by applying Krisp BVC upstream.
Indeed, the WER metric was generally much lower in this case compared to the AMI dataset.
In the BVC-VAD mode, where Whisper operated on original audio while leveraging Krisp BVC-processed audio for enhanced VAD, we observed an 18% improvement in WER.
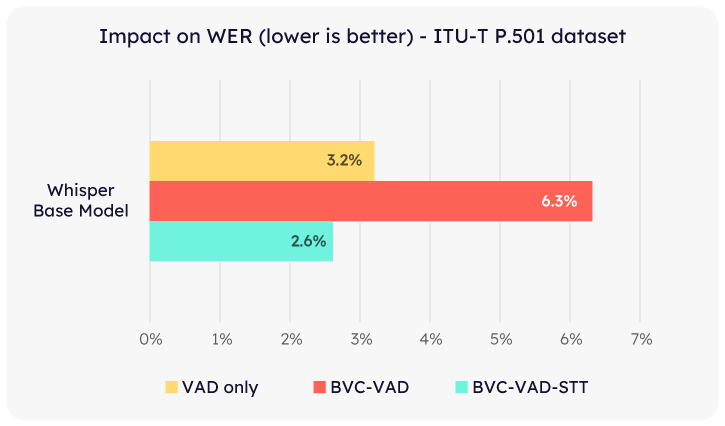
Conversely, in the BVC-VAD-STT mode — where Whisper processed Krisp-modified audio—the WER increased by about 2x, although the absolute WER number is still relatively low. This increase is attributed to Whisper never encountering Krisp NC-processed audio during its training, which could cause suboptimal performance for such modified audio.
💡Note that WER% results in BVC-VAD-STT mode could be very different on other datasets and STT engines. We recommend experimenting with both BVC-VAD and BVC-VAD-STT modes to determine the optimal audio pipeline setup for you.
Overall, these evaluations demonstrate that incorporating Krisp BVC into AI Voice Agents pipelines substantially improves turn-taking and speech recognition quality, especially in real-world scenarios where background noise and secondary conversations are prevalent.