The power of Krisp lies in its AI-based noise-cancellation algorithm—which we are constantly perfecting. Noise cancellation comes with distinct technical challenges: Namely, how do we remove distracting background noise while preserving human voice? If the app overcorrects on noise removal, the speaker’s voice will sound robotic. If it overcorrects on voice preservation, unwanted sounds will remain.
In each node of the audio pipeline, there are standardized methods for measuring the quality. In this blog, we’re going to deep dive into the nuances and challenges of software-based real-time working Noise Cancellation (NC) quality evaluations. We’ll show you how we do algorithm testing here at Krisp. But first, let’s begin with the basics.
What affects sound quality?
Our perception
Hearing is a physiological process and is based on human perception. Sound waves reach your ears and create an auditory perception that varies depending on the medium through which it traveled and the way your particular ears are structured. For example, you will perceive the same sound differently in the air versus in water. Another example is computer-generated audio that some people hear as “yanny” and others as “laurel.” Check it out below. What do you hear?
So, sound quality is based on our perception, which leads to a strong subjectivity factor.
Microphones and speakers
Another factor affecting overall sound quality is the audio recording and reproduction device used. Microphones can introduce specific audible and inaudible distortions like clipping, choppy voice, or suppressed frequency ranges. Moreover, they capture background noises and voices along with the main speaker’s voice. Though there are devices that have built-in noise cancellation, these kinds of hardware solutions are often not affordable for everyone or don’t eliminate the background noise completely.
In contrast, Krisp provides an AI-based software solution that increases the call quality with any device by effectively identifying and removing unwanted sounds. Developing and perfecting this app has unique challenges. Let’s dive into how we at Krisp test our noise-cancellation algorithm.
3 testing challenges of noise-cancellation algorithms
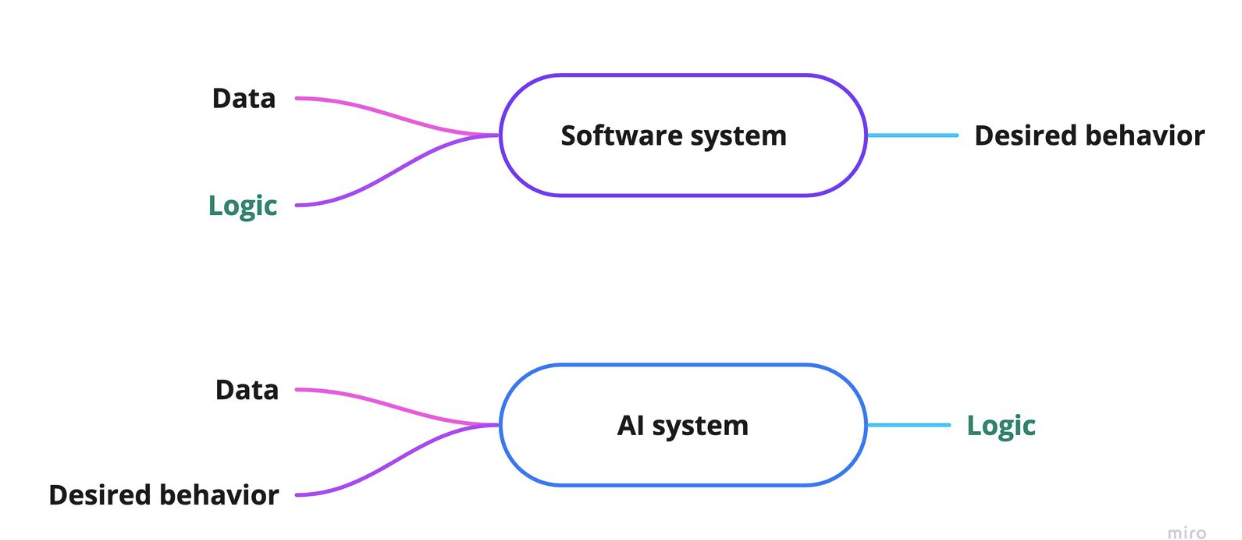
1. AI-based system testing is different from non-AI-based system testing.
The first challenge of NC algorithm quality assurance is that we’re dealing with an AI-based system. AI testing, in general, is different from non-AI-based software testing. In the case of non-AI-based software testing, the test subject is the predefined desiredbehavior. In the case of AI testing, however, the test subject is the logic of the system. See Figure 1 below.
Figure 1: Testing flow of Software and AI systems
2. Noise cancellation has tradeoffs.
The second challenge is that we always need to consider the possible tradeoffs of the system.
NC aggressiveness
One such tradeoff is the NC aggressiveness, which is the level of noise cancellation we apply. If the level is too low, distracting sounds still come through. If the level is too high, the speaker’s voice sounds robotic. The NC algorithm must find the golden mean where it eliminates all of the background noises while preserving the speaker’s voice.
Resource usage vs. quality
Another tradeoff is between resource usage and quality. Normally, the more extensive the neural network, the better work it will do. But the machines that are meant to run real-time working NC algorithms are supposed to have limited resources. So we need to assess consumed resources, like CPU usage, memory allocation, and power consumption to verify it’s working on-device with the expected quality. In addition, SDKs doing real-time noise cancellation need to be verified on multiple platforms, such as Mac, Windows, and iOS.
3. Audio quality can be affected by microphones and at multiple points along the journey.
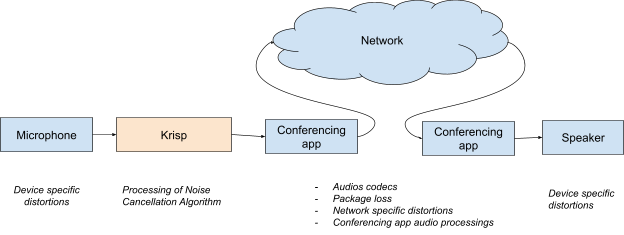
The third challenge of NC algorithm quality assurance is that microphone devices can add their own distortions. Plus, there are other factors impacting the audio quality as well. Before reaching the other side of the conferencing call, audio makes a long journey (see Figure 2). Each step could add its own degradations. A network can cause packet loss and other artifacts, which may lead to degradations in the output signal. On top of that, the sound-amplifying device in the final point should be qualified enough to replicate the audio with high fidelity.
Figure 2: Audio Signal Processing Pipeline
Speech quality testing: Subjective evaluations
The straightforward approach to Noise Cancellation quality evaluation is to listen to its output—in technical terms, conduct subjective evaluations. People of different ages, ear structures, or even having different moods may perceive the same piece of audio differently. No doubt, this leads to a subjective bias. To decrease that bias as much as possible, the standard process for subjective tests has been introduced.
ITU-R BS.1284-2 establishes the recommended standardized setup for conducting subjective tests. To get accurate results, you need to have diverse listeners as much as possible. More opinions, lower bias. The listeners rate the quality of audio on a scale of 1 to 5, where 5 corresponds to the highest possible quality and 1 to the lowest.
In our case, the score represents a healthy average of intelligibility of the voice and audibility of residual noise (if any). The mean opinion score (MOS) comes from the arithmetic mean of all of the listeners’ scores.
Quality of the Audio
MOS Score
Excellent
5
Good
4
Fair
3
Poor
2
Bad
1
Figure 3: MOS score rating description
Speech quality testing: Objective evaluations
Though subjective tests are precise, they can be very costly and time-consuming, as they require a lot of human, time, and financial resources. Consider a situation having many variants of an NC algorithm with two or more NC algorithms under test. Conducting subjective evaluations for the algorithms may delay the early feedback, making it impossible to deliver the algorithms promptly.
To overcome these issues, we’re also considering objective evaluation metrics. Some of these metrics tend to be highly correlated with subjective scores. Unlike subjective scores, objective evaluations are repeatable. No matter how many times you evaluate the same algorithm, you will get the same scores—something that is not guaranteed with subjective metrics. Objective evaluations make it possible to evaluate many NC algorithms in the same conditions without wasting extra effort and time.
There are a few objective evaluation metrics designed for different use cases. Each has its own logic for audio assessment. Let’s review some of the metrics that we’re currently considering.
PESQ (Perceptual Evaluation of Speech Quality) is the most used metric in Research, though it’s not for NC quality evaluations explicitly, but for measuring speech quality after passing through the network and codec-related distortions. It is standardized as Recommendation ITU-T P.862. Its result represents the mean opinion score (MOS) that covers a scale from 1 (bad) to 5 (excellent).
POLQA (Perceptual Objective Listening Quality Analysis) is an upgraded version of PESQ that provides an advanced level of benchmarking accuracy and adds significant new capabilities for super-wideband (HD) and full-band speech signals. It’s standardized as Recommendation ITU-T P.863. POLQA has the same MOS scoring scale as its predecessor PESQ, though it’s for the same use case of evaluating quality related to codec distortions.
3QUEST (3-fold Quality Evaluation of Speech in Telecommunications) was designed to assess the background noise separately in a transmitted signal. Thus, it returns Speech-MOS (S-MOS), Noise-MOS (N-MOS), and General-MOS (G-MOS) values on a scale of 1 (bad) to 5 (excellent). G-MOS is a weighted average of the other two. It’s standardized as Recommendation ITU-T P.835. Based on our experience, 3QUEST is the most suitable objective metric for NC evaluations.
NISQA (Non-intrusive Objective Speech Quality Assessment) is a relatively new metric. Unlike the above-listed metrics, it doesn’t require the reference clean speech audio file. It’s standardized from ITU-T Rec. P.800 series. Besides MOS score, NISQA provides a prediction of the four speech quality dimensions: Noisiness, Coloration, Discontinuity, and Loudness.
How we generate test datasets
A straightforward approach to generating test datasets is to mix the clean voice and noise with the desired SNR (Signal-to-Noise Ratio) using an audio editor or other tools. Though these recordings don’t simulate the real use case and are artificial, we use such recordings in the initial testing phases as they are easy to collect and can catch obvious quality issues in the early stages of development.
To have more accurate recordings for qualitative tests and evaluations, we’re collaborating with well-equipped audio labs to get recordings with predefined use cases. A real use case is being simulated in ETSI rooms and being recorded with high-quality microphones, where:
The spoken sentences are phonetically balanced, intended to cover all possible sounds in a certain language.
There are a few speakers in the same recordings, intended to cover speaker-independency tests.
Recordings are done with different languages, intended to cover language independency tests.
They are simulating various noises with different noise levels and recording them along with voice with the same mic.
As you can see, a lot of use cases are covered with the above-mentioned datasets. However, to ensure the Noise Cancellation algorithmic quality, we still need to consider some test scenarios that are outside of these recordings’ scope. To fill that gap, we also perform in-house recordings.
To ensure Krisp works with any device, we need to test it with a lot of devices. However, testing with all possible devices is practically impossible and may not be necessary. Instead, we’ve identified the top devices used by our users and targeted the testing on those devices. Currently, we have an in-house “device farm” with almost 50 mics, and we’re continuously adding the latest available mics.
Figure 4: Some microphones from our test set
As a part of the NC algorithm, Krisp also removes the room echo, or in more technical terms, reverberation. Hence we’re considering a lot of rooms with different acoustic setups to guarantee meaningful coverage of reverberant cases.
Noise cancellation and speech quality: The eternal tradeoff
Again, when evaluating the quality of Krisp’s NC algorithm, we must strike the right balance between removing background noise and preserving the speaker’s voice. There is an eternal tradeoff between these two criteria.
To gain a complete picture, we’re considering different test scenarios/datasets along with corresponding applicable metrics. There is no single metric reflecting the best representative value for the quality assessment. Each evaluation metric is designed for certain use cases; they are complementing each other rather than replacing. Testing an NC algorithm with several evaluation metrics allows us to have a more comprehensive picture to assess the audio quality from different standpoints.