Krisp AI Meeting Note Taker
Voice Notes and Memo Recorder
Real-time speech-to-speech translation built for accuracy-critical applications. 61 languages, any-to-any pair.
Start speaking, we'll translate in real time.
Built inside enterprise contact centers, where accuracy is not optional
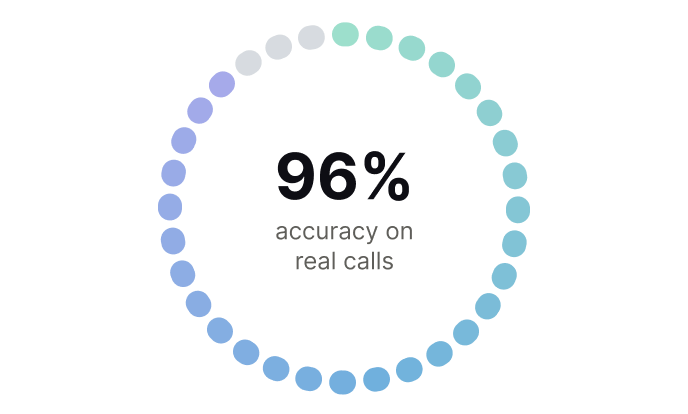

The core engine behind live enterprise contact center deployments, now available as an API.
A real-time translation API you can self-serve from minute one. Sign up, get an API key, and start translating. No sales call, no procurement cycle.
# 1. Get a short-lived session key
session_key = get_vt_session_key(API_KEY)["session_key"]
# 2. Build a session config
config = VtSessionConfig(
auth_token = session_key,
input_language_code = "en-US", # BCP-47, source
output_language_code = "fr-FR", # BCP-47, target
voice = VtVoice.FEMALE, # output voice
custom_vocabulary = VtCustomVocabularyData(
vocabulary = ["Krisp", "AcmeCorp"], # ASR boost for domain terms (optional)
dictionary = { # force specific translations (optional)
"hello": "bonjour",
"goodbye": "au revoir",
},
),
metadata = VtSessionMetadata(
reference_id = "your-reference-id", # optional correlation id for support
),
background_voice_cancellation = True,
)
# 3. Open the session with callbacks
vt = Vt.create(
config,
original_transcript_callback = on_source_text, # source text
translated_transcript_callback = on_target_text, # translated text
audio_result_callback = on_translated_audio, # translated PCM
event_callback = on_event, # flow control
error_callback = on_error, # error handling
)
# 4. Stream audio - one PCM chunk per 20ms
# 16 kHz mono s16le = 640 bytes per chunk
for chunk in pcm_chunks:
vt.process(chunk)
sleep(0.020)
# 5. Close when done
sleep(2.0) # let final events land
vt.close()# Source transcript - interim partials and final utterances
def on_source_text(r):
r.transcript # str - interim partial OR final utterance
r.type # INTERIM | FINAL
r.chunk_id # groups interim updates for one utterance
r.duration # ms covered by this transcript
r.timestamp # server-side start time
# Translated transcript - same shape as source
def on_target_text(r):
r.transcript # translated text
r.type # INTERIM | FINAL
# Translated audio - raw PCM bytes
def on_translated_audio(r):
r.output_samples # bytes - int16 PCM, 16 kHz mono
# Flow control events
def on_event(e): # INPUT_ALLOWED | INPUT_NOT_ALLOWED
...
# Error handling with recovery hints
def on_error(e):
if vt_is_retryable(e):
... # exponential backoff, reconnect
log(vt_recovery_hint(e))// Single JSON config - sent once when the WebSocket session opens
// wss://streaming.krisp.ai/vt?authorization=Api-Key SESSION_KEY
{
"config": {
"source_language": "en-US",
"target_language": "es-US",
"voice": "female",
"vocabulary": ["Lisinopril", "metformin", "HIPAA"],
"translation_dictionary": [
{ "source": "copay", "target": "copago" },
{ "source": "referral", "target": "remisión" }
],
"transcript": {
"interim": true,
"final": true,
"translate": true
},
"features": {
"background_voice_cancellation": true
}
}
}const { Vt, VtSessionConfig, VtCustomVocabularyData,
VtVoice, mintVtSessionKey } = require('krisp-audio-node-sdk').vt;
// 1. Get a short-lived session key
const { session_key } = await mintVtSessionKey(API_KEY);
// 2. Build a session config
const config = new VtSessionConfig({
authToken: session_key,
inputLanguageCode: 'en-US', // BCP-47, source
outputLanguageCode: 'fr-FR', // BCP-47, target
voice: VtVoice.FEMALE, // output voice
customVocabulary: new VtCustomVocabularyData({
vocabulary: ['Krisp', 'AcmeCorp'], // ASR boost for domain terms (optional)
dictionary: { // force specific translations (optional)
'hello': 'bonjour',
'goodbye': 'au revoir',
},
}),
});
// 3. Open the session with callbacks
const vt = await Vt.create(
config,
onSourceText, // original transcript
onTargetText, // translated transcript
onTranslatedAudio, // translated PCM
onEvent, // flow control
onError, // error handling
);
// 4. Stream audio - one PCM chunk per 20 ms
// 16 kHz mono s16le = 640 bytes per chunk
for (const chunk of pcmChunks) {
vt.process(chunk);
await sleep(20);
}
// 5. Close when done
await sleep(2000); // let final events land
await vt.close();// Source transcript - interim partials and final utterances
function onSourceText(r) {
r.transcript // string - interim partial OR final utterance
r.type // VtTranscriptionType.INTERIM | FINAL
r.chunkId // groups interim updates for one utterance
r.duration // ms covered by this transcript
r.timestamp // server-side start time
}
// Translated transcript - same shape as source
function onTargetText(r) {
r.transcript // translated text
r.type // VtTranscriptionType.INTERIM | FINAL
}
// Translated audio - raw PCM Buffer
function onTranslatedAudio(r) {
r.outputSamples // Buffer - int16 PCM, 16 kHz mono
}
// Flow control events
function onEvent(e) { } // VtEventType.INPUT_ALLOWED | INPUT_NOT_ALLOWED
// Error handling with recovery hints
function onError(e) {
if (vtIsRetryable(e)) {
// exponential backoff, reconnect
}
console.log(vtRecoveryHint(e));
}
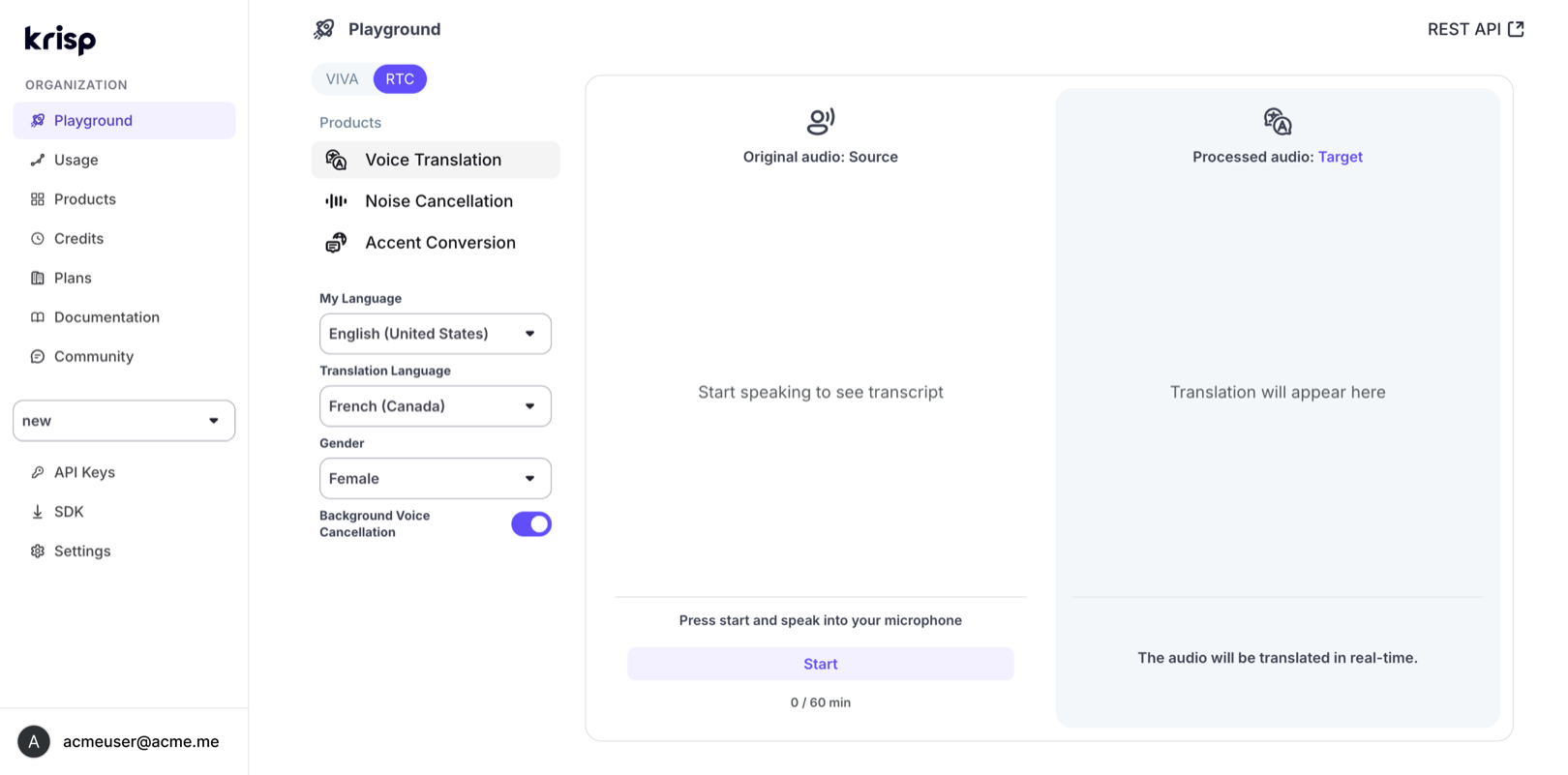
See It In Action
Both powered by 8 years of production audio and a trillion+ minutes processed.
Security & Privacy
The same security posture that serves enterprise contact centers, now available to every developer building with the API.
Pricing
Multiple subscription tiers, from self-serve to enterprise. 60 minutes of free translation credit on every new account.
The Translation API is one part of the Krisp audio stack. Two more SDK families are available for teams building voice-first products.
VIVA SDK
Voice Isolation, Turn Prediction, Interruption Prediction, and VAD, lightweight models that sit between real-world audio and your AI agent.
RTC SDK
Accent Conversion, Background Voice Cancellation, and Noise Cancellation, real-time processing for contact centers and communication platforms.
If you are building accuracy-critical solution. Get your API key today.



