In today’s world, browsers have become an integral part of our daily lives. Although Krisp worked on various native libraries for most platforms in use (Windows, Mac, Linux, Android, IOS), there were still many use cases where Krisp SDK was needed in the context of web applications. This article summarizes our journey of creating world-class noise cancellation SDKs for web usage. We believe this is a unique usage of Web Assembly, which showcases the unlimited possibilities that WASM has to offer. We put a lot of time and effort into this project and have delivered a game-changing JS SDK, enabling many products to level up their web-based real-time communication.
Challenges
Processing audio in the browser is more challenging than it may seem at first glance. We faced different challenges. Some were well-known and had defined technical solutions. In contrast, some challenges were particular to our use case and we had to get creative. Let’s review some of our main challenges and discuss the solutions we came up with.
Run C++ directly on the web.
Our first challenge when working on Krisp’s JS SDK was that our core SDK is C++ based and we needed to find a way to use our core SDK’s functionality inside a browser. We found a well-known solution for that: WASM (WebAssembly). This binary instruction format allows running programming languages such as C and C++ in the browser and achieving near-native performance on the web. To compile our C++ library into a WASM module, we used Emscripten: a complete compiler toolchain to WebAssembly, with a primary focus on performance in web platforms. After compiling C++ into a WASM module, we can import that module to our javascript/typescript project and use it (see Figure 1).

Figure 1. WASM module usage
Using our NC models
After understanding how to use our C++ code, we faced another problem: using our noise cancellation models. Up until this point, we were using our models in a native context and we didn’t have to worry about the size of our models that much. But everything changes in the context of web applications where you can’t load 30 or 40 MB of data every time while opening the application. To solve this problem, our research team worked on smaller yet fully functional models focused on performance. In Figure 2, you can see the comparison between our regular and small models.
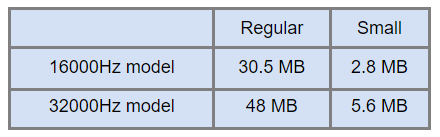
Figure 2. Model size comparison
128 samples per frame limitation
With native development, you have flexibility and control over your audio flow. However, there are some limitations you have to consider while working with audio inside a browser. Audio circulates in frames (see Figure 3). Each frame consists of 128 samples (a sample is just a number describing the sound). There is also a term called sample rate – the number of samples we will receive per second. The sample rate may vary based on the device (you may have already seen the sample rate characteristic in audio devices’ descriptions).
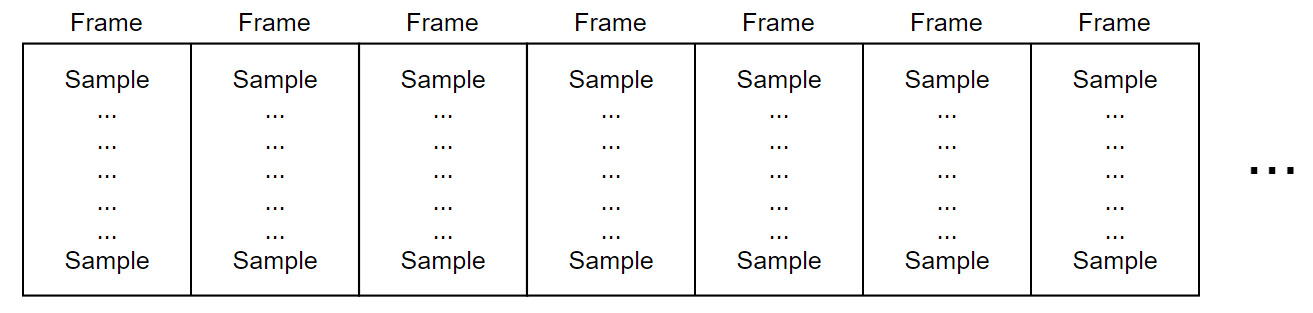
Figure 3. Audio frames in web
Now, with this information, it is reasonably easy to understand how many seconds/milliseconds of audio is stored in the given number of samples based on our sample rate. The sample count divided by the sample rate will provide us with the number of seconds stored in that sample count. To make the calculation even more helpful, we can multiply the result by 1000 to get the answer in milliseconds.
Example: Let’s say our sample rate is 48000 Hz, and we need to understand the duration of audio stored in one frame. One frame holds 128 samples; therefore, the calculation is as follows:
(128 / 48000) * 1000 = 2.66ms.
So what exactly was our problem? Our SDK needs at least 10 milliseconds of audio to process, while the browser gives and expects to receive 128 sample frames. Our solution was to create a buffering system that will:
a) Accumulate 10 milliseconds of audio and send that chunk to our WASM module to process b) Take the processed audio from the WASM module, split it into 128 sample frames, and return it to the browser (See Figure 4).
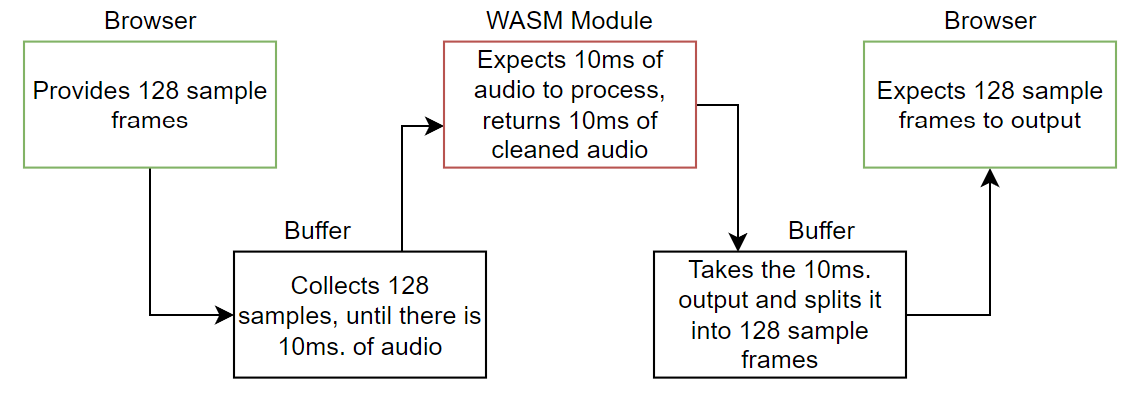
Figure 4. A simplified diagram of our buffering system operations
After handling these initial challenges, nothing stopped us from creating our first version of Krisp JS SDK.
The first version of Krisp JS SDK

Figure 5. Simplified diagram of our first version of Krisp JS SDK
In Figure 5, you can see the simplified architecture diagram of our prototype of JS SDK.
C++ side
Krisp Audio SDK is the C++ library we needed to run in Javascript. We also added a 128-sample state machine to it to track the state of the audio data and ensure audio consistency. Krisp WASM Processor is a middleware to create Emscripten bindings, allowing us to use methods from C++ on our Javascript side. As you can see, a buffering system is included here, which works with the state machine. Everything is compiled from this point, and we get our WASM Module.
JS Side and Web Audio API
We needed to work with Web Audio API to process the audio on our javascript side. Web Audio API provides a robust system to process audio on the web. Three main concepts were important in our use case: AudioContext, AudioWorkletProcessor, and AudioWorkletNode. Let’s go over each of these shortly. AudioContext is basically an audio graph that lets you manipulate audio sources and process the audio with various effects and processors before passing it into the audio destination (see Figure 6).

Figure 6. The basic structure of AudioContext
AudioWorkletProcessor is capable of receiving input audio and setting the output audio. The interesting part is that you can manipulate audio in its process() method in between. In our case, we imported the WASM Module to the same krisp.processor.js file and started using it in the process() method, taking the cleaned audio and setting it as output.
After writing the necessary code for the processor, the final step would be to integrate that processor into the AudioContext graph somehow. For that, in our krispsdk.js file, we created our filter node using AudioWorkletNode, which takes our processor and adds it to the audio context’s graph.

Simplified look at the connection between AudioWorkletNode, AudioWorkletProcessor, and AudioContext
So, at this point, we already got our first working prototype, but there were several issues with it.
Issues with our first version
Buffering system on the C++ side
Although our initial version worked, we encountered some issues with our buffering system. First of all, we implemented all the buffering logic on our C++ side, and as a result, that system was getting compiled into the WASM Module. And although we implemented logic to ensure that audio was consistent, the buffer’s location could have been more practical, as there was still a chance of losing audio data between processing. It is essential to note that the buffering system was an additional middleware.
Terminating AudioWorkletNode
Another issue was that we couldn’t entirely terminate our AudioWorkletNode, which resulted in multiple memory leak issues. Also, because of the same problem, we couldn’t handle device change based on the sample rate. We should re-initialize our SDK with a proper NC model optimal for that sample rate to ensure the best quality.
Providing NC models separately
And our last issue was that we were providing our NC models separately in a folder so that they could be hosted on our client’s side and imported to JS SDK with static URLs. Seeing all these issues, we started working on solutions and came up with a new version of JS SDK.
The new version of Krisp JS SDK
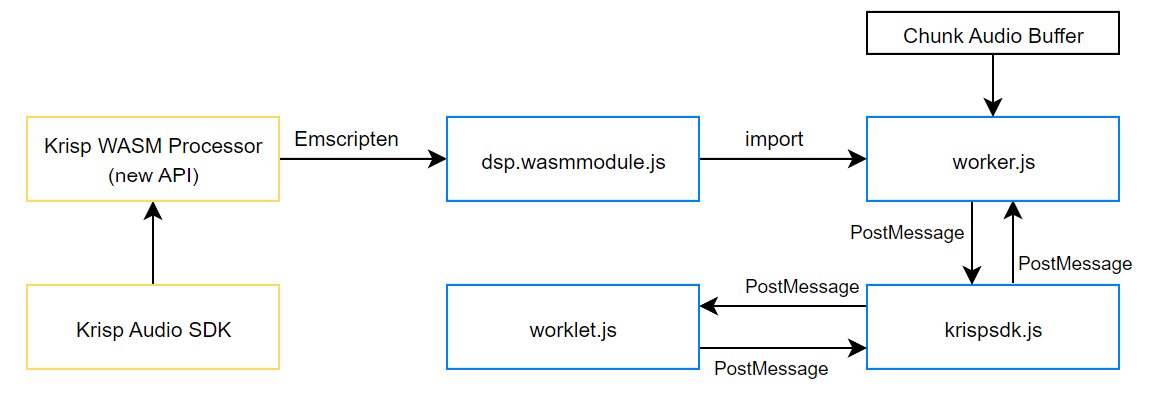
Figure 7. The new architecture of Krisp JS SDK
We developed core architectural improvements to eliminate the problems mentioned above (see Figure 7). Let’s go over each of them.
- We moved all the buffering systems to the JS side so that our core SDK would receive data in the expected form, which resulted in a more straightforward implementation and more consistent behavior of our buffers. We started collecting audio and checking for the accumulated audio size. When we have our target 10ms audio in our buffer, we provide that 10ms chunk directly to SDK (So we are not sending every audio frame separately, which is a huge optimization.) With the same logic, our custom buffer class takes the cleaned audio and delivers it back to the browser, split into 128 sample frames.
- We moved all the audio processing to a new, separate web worker thread to handle memory leak issues, which worked perfectly. After terminating the worker, everything inside of it gets terminated as well. Although there will remain an open thread, we solved the main issue with loading and keeping multiple WASM Modules. Clients can implement device change handling logic to achieve the best possible audio quality thanks to this change.
- We decided to modify our Emscripten method bindings to achieve more flexibility in JS SDK. In the first version, we had only three methods, which were combinations of methods called from the C++ side: init(), toggle(), and dispose(). With the new version, we came to the idea of having a 1-to-1 method binding from C++ to the JS side, allowing us to work with audio on a more advanced level while in JS.For example, while calling init() before, it called multiple methods, including session and its id creation. With the new bindings, we get the session creation method separately, which means together with our in-worker processing logic, we can run multiple instances of NC sessions (for example, run for both microphone and speaker)
- And our last improvement was related to our NC models’ delivery. Instead of handling them separately, we packed them into one Emscripten .data file. Later, we also added options to choose which NC models we should preload and which should only be loaded when needed.
As you can see in the new architecture, all the communication goes through krispsdk.js which is our main thread. We initialize the worker and worklet from it, and to make them communicate with each other, we used PostMessages. But there was room for optimization for this – to pass one chunk of audio to SDK and back, we were sending 4 PostMessages. To solve this problem, we came up with two solutions.
- The first option was using SharedArrayBuffer so the worker and worklet could communicate directly. This solution works, but it needs to be more practical to make it the main way of operation, as SharedArrayBuffer got some security requirements. To be able to use it, you should set specific headers:We implemented this solution and created an optional flag, which you can enable during the initialization.
- The final solution we came up with was to share a port between the worker and the worklet and send post messages directly to the same port. This optimization resulted in a 50% PostMessage cut, and now to process one chunk of audio, we are using only 2 PostMessages (See Figure 8).
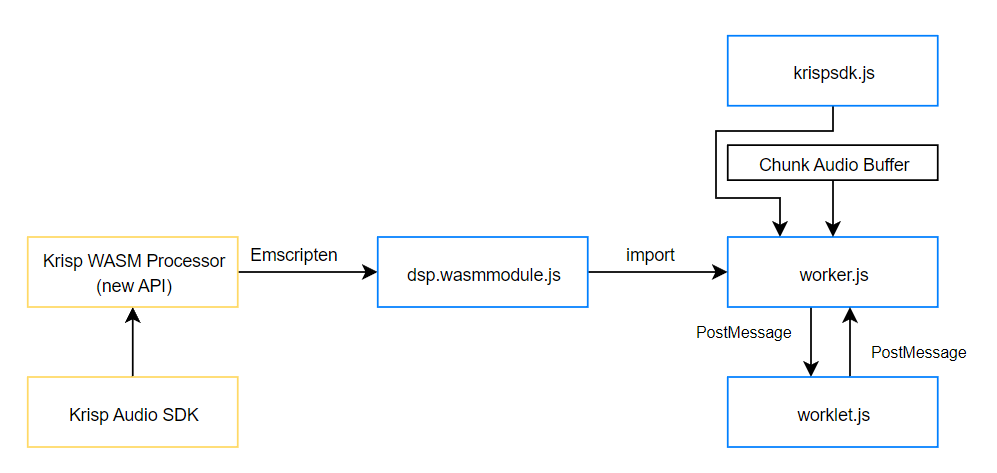
Figure 8. The improved architecture of the new version of Krisp JS SDK
Summary
In conclusion, developing a noise cancellation SDK for web usage comes with its own set of unique challenges. Through hard work and ingenuity, the team was able to create a game-changing JS SDK that allows for web-based real-time communication with top-tier noise cancellation. The use of Web Assembly showcased the endless possibilities of this technology. The team’s efforts demonstrate that with the right approach, web-based noise cancellation can be achieved with near-native performance.
Try next-level audio and voice technologies
Krisp licenses its SDKs to embed directly into applications and devices. Learn more about Krisp’s SDKs and begin your evaluation today.

References
This article was written by Arman Jivanyan, BSc in Computer Science, Software Engineer at Krisp.