Introducing Krisp’s Turn-Taking v2
We’ve already discussed the challenges of turn-taking in conversational AI in this blog post.
Now, we’re excited to announce our newest Turn-Taking model, available as part of Krisp’s VIVA SDK.
In this article, we’ll walk through the technology behind the new model and share our latest testing results. The new generation of models is more streamlined than ever—making it simple to integrate Voice Isolation, Turn-Taking, and VAD into your Voice AI pipelines.
If you’d like to see how Krisp’s VIVA SDK can enhance your Voice AI agent experience, apply now from our Developers page.
How the New Model Works
Our latest model predicts End-of-Turns using only audio input—perfect for real-time conversational systems like human-bot interactions.
Compared to v1, krisp-viva-tt-v2 represents a major step forward. It was trained on a more diverse and better-structured dataset, with richer data augmentations that help the model perform more reliably in real-world conditions.
Key Improvements in v2
- Greater robustness in noisy environments
- Higher accuracy when paired with Krisp’s Voice Isolation models
- Faster and more stable turn detection in live conversations
Testing Results
Testing on Clean Audio
We evaluated both model versions on ~1800 audio samples from real conversations, including ~1000 “hold” cases and ~800 “shift” cases, with mild background noise.
Although the numerical difference between versions is small on this clean dataset, the results show that v2 achieves faster mean shift prediction time at the same false positive rate.
| Model |
Balanced Accuracy |
AUC |
F1 Score |
| krisp-viva-tt-v1 |
0.82 |
0.89 |
0.804 |
| krisp-viva-tt-v2 |
0.823 |
0.904 |
0.813 |
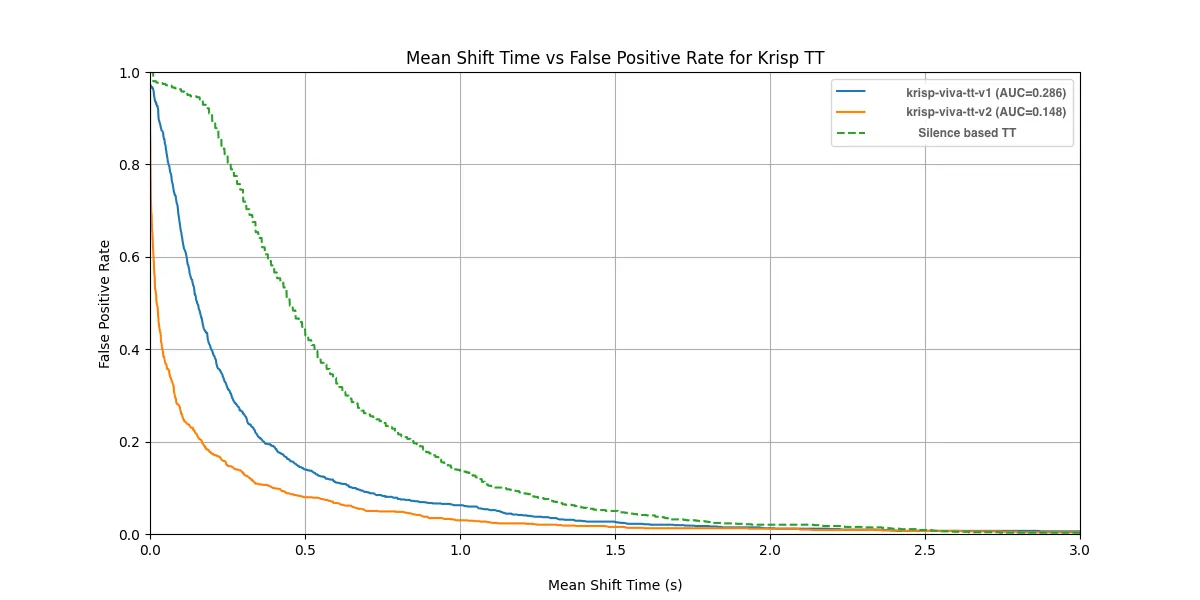
Insight: Even in clean audio conditions, krisp-viva-tt-v2 offers slightly better prediction stability and overall performance.
Testing on Noisy Audio
Next, we evaluated the models on noisy audio mixes at 5 dB, 10 dB, and 15 dB noise levels. Two scenarios were tested:
- Directly on the noisy dataset
- On the same dataset after processing through the Krisp VIVA Voice Isolation model
In both scenarios, krisp-viva-tt-v2 consistently outperformed v1.
| Model |
Balanced Accuracy |
AUC |
F1 Score |
| krisp-viva-tt-v1 |
0.723 |
0.799 |
0.71 |
| krisp-viva-tt-v2 |
0.768 |
0.842 |
0.757 |
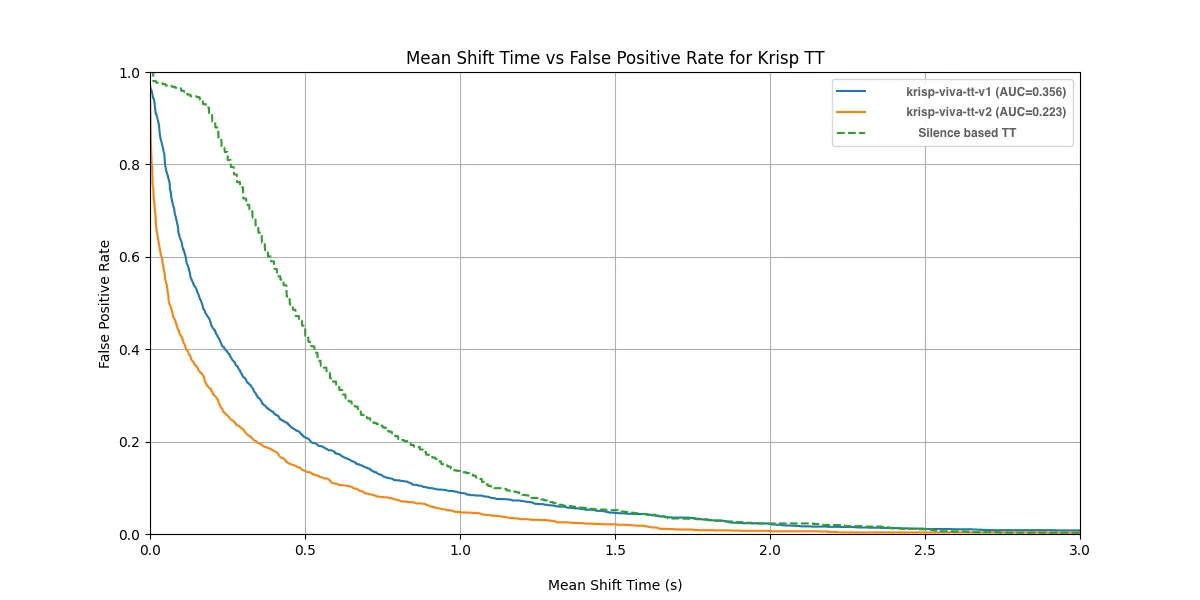
Insight: krisp-viva-tt-v2 delivers up to a 6% improvement in F1 score under noisy conditions, demonstrating greater resilience in real-world environments.
Testing After Noise and Voice Removal
Finally, we tested both models on the same noisy dataset after applying background noise and voice removal with the krisp-viva-tel-v2 model.
| Model |
Balanced Accuracy |
AUC |
F1 Score |
| krisp-viva-tt-v1 |
0.787 |
0.854 |
0.775 |
| krisp-viva-tt-v2 |
0.816 |
0.885 |
0.808 |
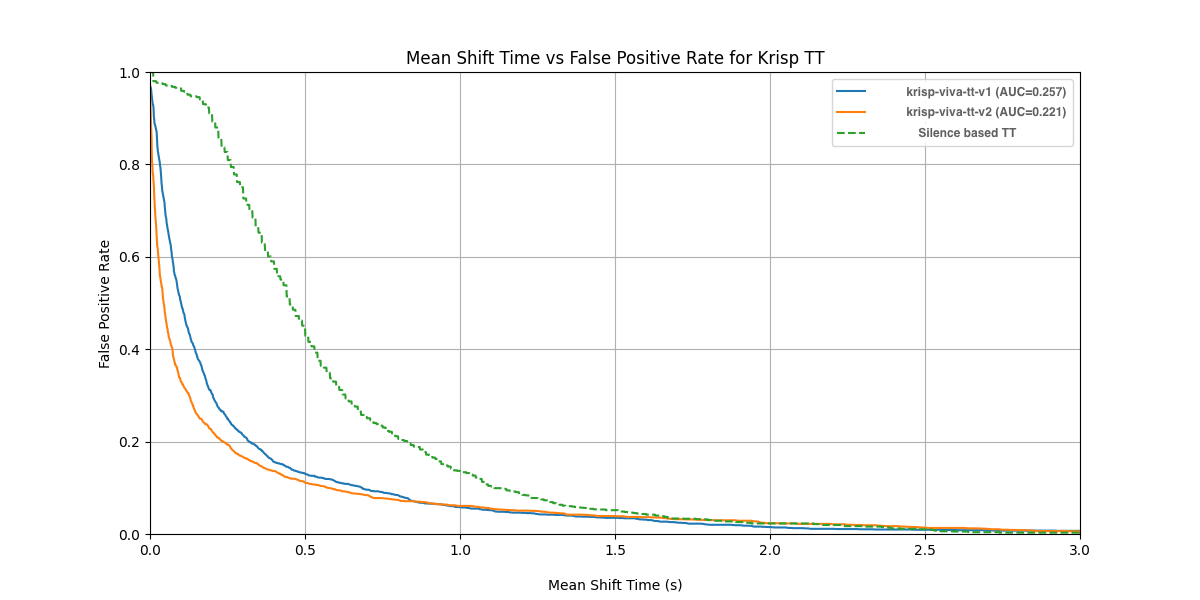
Insight: When combined with Krisp’s Voice Isolation technology, v2 achieves even greater accuracy and stability.
Conclusion
The new krisp-viva-tt-v2 model marks a significant leap forward in real-time conversation handling for Voice AI. With improved robustness against noise and smoother integration with Krisp’s other models, developers can now build faster, smarter, and more natural-sounding conversational agents.
Explore the VIVA SDK today and see how Krisp’s advanced models can elevate your Voice AI experience.