


Individuals and Freelancers
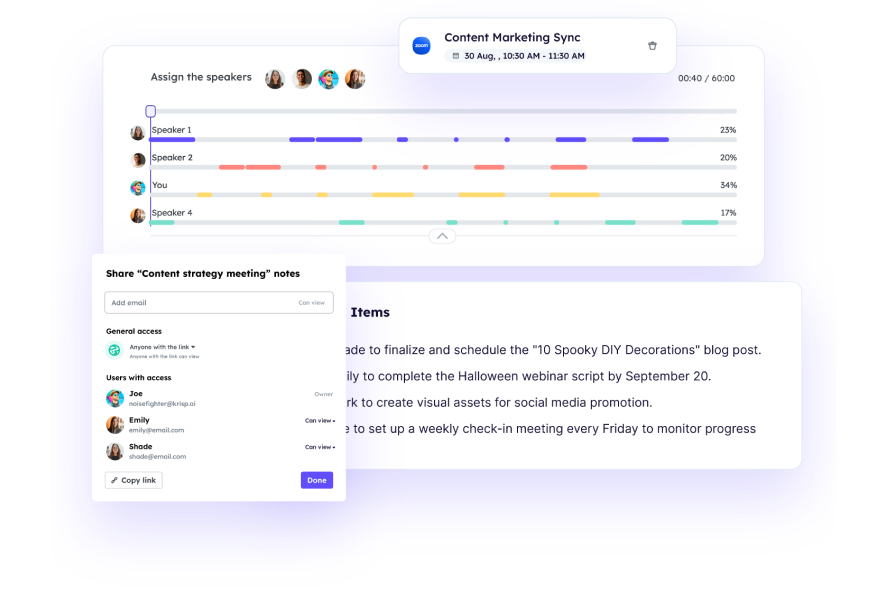
Professional calls from any location. Focus on discussions without missing details. Review key points efficiently.
-
 Distraction-free calls
Distraction-free calls -
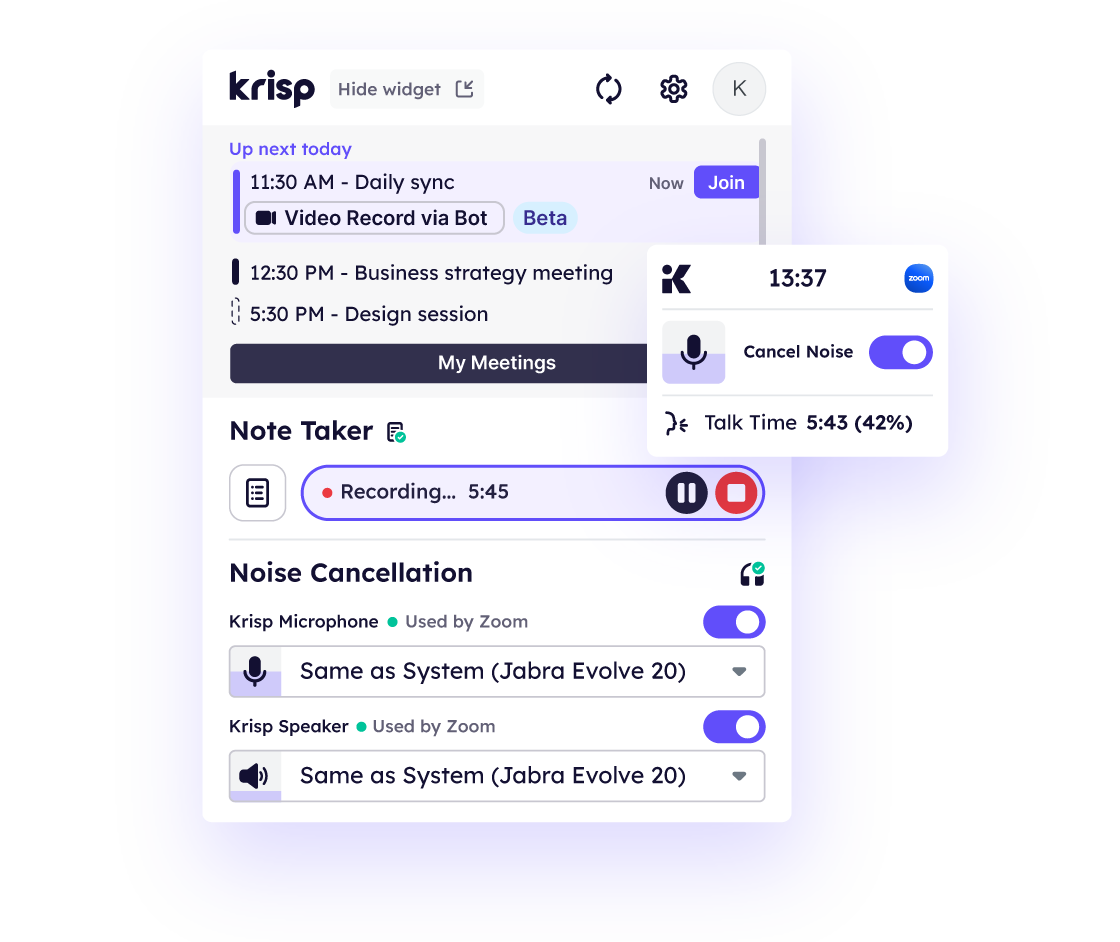
Complete capture of discussions
-
Quick review of key points and summary