In this article we discuss an outstanding problem in today’s Voice AI Agents – turn-taking. We examine why it is a hard problem and present a solution in
Krisp’s VIVA SDK.
We also benchmark the Krisp solution against some of the established solutions in the market.
Note: The Turn-Taking model is included in the VIVA SDK offering at no additional charge.
What is turn-taking?
Turn-taking is the fundamental mechanism by which participants in a conversation coordinate who speaks when. While seemingly effortless in human interaction, in human to AI agent conversations modeling this process computationally is highly complex. In the context of Voice AI Agents (including voice assistants, customer support bots, and AI meeting agents), turn-taking decides when the agent should speak, listen, or remain silent.
Without effective turn-taking, even the most advanced dialogue systems can come across as unnatural, unresponsive, and frustrating to use. A precise and lightweight turn-taking model enables natural, seamless conversations by minimizing interruptions and awkward pauses while adapting in real time to human cues such as hesitations, prosody, and pauses.
In general, turn-taking includes the following tasks:
- End-of-turn prediction – predicting when the current speaker is likely to finish their turn
- Backchannel prediction – detecting moments where a listener may provide short verbal acknowledgments like “uh-huh”, “yeah”, etc. to show engagement, without intending to take over the speaking turn.
In this article, we present our first audio-based turn-taking model, which focuses on the end-of-turn prediction task using only audio input. We chose to release the audio-based turn-taking model first, as it enables faster response times and a lightweight solution compared to text-based models, which usually require large architectures and depend on the availability of a streamable ASR providing real-time, accurate transcriptions.
Approaches to Turn-Taking
Solutions to Turn Taking problem are usually implemented in AI models, which use audio and/or text representation.
1. Audio-based
Audio-based approaches rely on analyzing acoustic and prosodic features of speech. These features include, changes in pitch, energy levels, intonation, pauses and speaking rate. By detecting silence or overlapping speech, the system predicts when the user has finished speaking and when it is safe to respond. For example, a sudden drop in energy followed by a pause can be interpreted as a turn-ending cue. Such models are effective in real-time, low-latency scenarios where immediate response timing is critical.
2. Text-based
Text-based solutions analyze the transcribed content of speech rather than the raw audio. These models detect linguistic cues that indicate turn completion, such as sentence boundaries, punctuation, discourse markers (e.g., “so,” “anyway”), natural language patterns or semantics (e.g., user might directly ask the bot not to speak). Text-based systems are often integrated with dialogue state tracking and natural language processing (NLP) modules, making them effective for scenarios where accurate semantic interpretation of user intent is essential. However, they may require larger neural network architectures to effectively analyze the linguistic content.
3. Audio-Text Multimodal (Fusion)
Multimodal solutions combine both acoustic and textual inputs, leveraging the strengths of each. While audio-based methods capture real-time prosodic cues, text-based analysis provides deeper semantic understanding. By integrating both modalities, fusion models can make accurate and context-aware predictions of turn boundaries. These systems are effective in complex, multi-turn conversations where relying on either audio or text alone might lead to errors in timing or intent detection.
Challenges of turn-taking
Hesitation and filler words
In natural dialogue, speakers often take a pause using fillers like “um” or “you know” without intending to give up their turn. For instance:
“I think we should, um, maybe –” [The agent jumps in, assuming the sentence is over]
Here, a turn-taking system must distinguish hesitation from completion, or risk interrupting too early.
Natural pauses vs. true end-of-turns
Pauses are not always indicators that a speaker has finished. For example:
“Yesterday I woke up early, then… [pause] I went to work…”
A model might misinterpret the pause as a turn boundary, generating a premature response and breaking the conversational flow.
Quick turn prediction
Minimizing response latency is essential for maintaining natural conversational flow. Humans tend to respond quickly, sometimes even reactively, when the end of the speech is obvious. If a model fails to predict the turn boundary fast enough, the system may sound sluggish or unnatural. The challenge is to trigger responses at just the right moment – early enough to sound fluid, but not so early that it risks interrupting the speaker.
Varying speaking styles and accents
People speak in diverse rhythms, intonations, and speeds. A fast speaker with sharp pitch drops might appear to end a sentence even when they haven’t. Conversely, a slow, melodic speaker may stretch syllables in ways that confuse timing-based systems. Modeling these variations effectively requires a neural network–based approach.
Krisp’s audio-based Turn-Taking model
Recently Krisp had released AI models for effective noise cancellation and voice isolation for Voice AI Agent use-cases, particularly improving pre-mature turn taking caused by background noise. See more details. This technology is widely deployed and has recently passed a 1B mins/month milestone.
It was only natural for us to take on a larger problem of turn-taking (TT). In this first iteration, we designed a lightweight, low-latency, audio-based turn-taking model optimized to run efficiently on a CPU. The Krisp TT model is built into Krisp’s VIVA SDK, where using the Python SDK you can easily chain it with the Voice Isolation models , placing it in front of a voice agents to create a complete, end‑to‑end conversational flow, as shown in the following diagram.
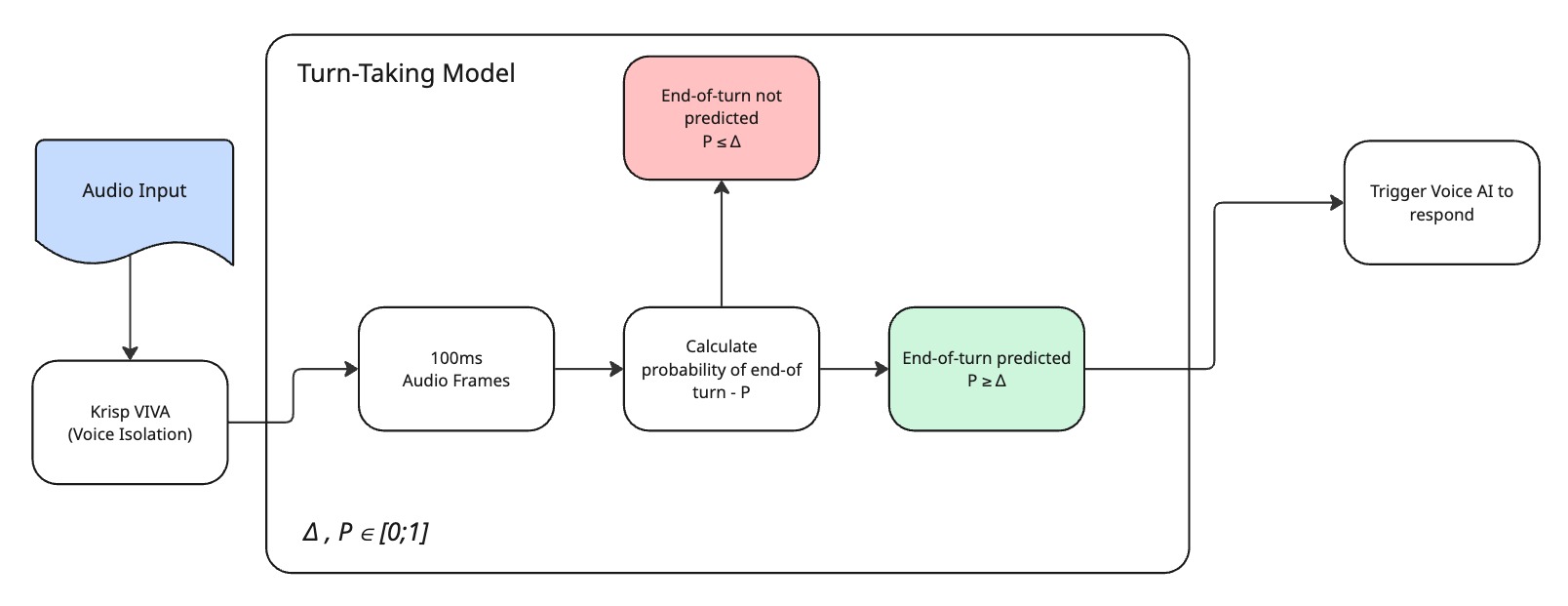
Here, the TT model continuously outputs a confidence score (probability) ranging from 0 to 1, indicating the likelihood of a shift – a point where a speaker is expected to finish their turn. It operates on 100ms audio frames, assigning a shift confidence score to each frame. To convert this score into a binary decision, we apply a configurable threshold. If the score exceeds this threshold (Δ), we interpret it as a shift (end of turn) prediction; otherwise, the model considers the current speaker is still holding the turn.
We also define a maximum hold duration, which defaults to 5 seconds. The model is designed such that, during uninterrupted silence, the confidence score gradually increases and reaches a value of 1 precisely at the end of this maximum hold period.
Comparison with other Turn-Taking models
Let’s take a closer look at how other solutions handle the turn-taking problem in comparison to Krisp.
Simple VAD (Voice Activity Detection)
The basic VAD-based approach is as straightforward as it gets – if you taken a pause in your speech, you have probably have finished your turn. Technically, once a few seconds of (usually configurable) silence is detected, the system assumes the speaker has finished and hands over the turn. While efficient, this method lacks awareness of conversational context and often struggles with natural pauses or hesitant speech. In our comparisons, we use the Silero-VAD model with a 1-second silence detection window as a simple VAD-based turn-taking approach.
SmartTurn
SmartTurn v1 and SmartTurn v2 by Pipecat are open-source AI models, designed to detect exactly when a speaker has finished their turn. We picked them for in-depth comparison because like Krisp TT, they are audio-based models.
Interestingly, SmartTurn models introduce a hybrid strategy. They first wait for 200ms of silence detected by Silero VAD, then evaluate whether a turn shift should occur. If the confidence is too low to switch, the system defers the decision. However, if silence persists for 3 seconds (default value, configurable parameter in SmartTurn), it forcefully initiates the turn transition. This layered approach aims to strike a balance between speed and caution in handling user pauses.
Tested Models
The following table gives a high-level comparison between the contenders
| Attribute |
Krisp TT |
SmartTurn v1 |
SmartTurn v2 |
VAD-based TT |
| Model Parameters count |
6.1M |
581M |
95M |
260k |
| Model Size |
65 MB |
2.3 GB |
360 MB |
2.3 MB |
| Recommended Execution |
On CPU |
On GPU |
On GPU |
On CPU |
| Overall Accuracy |
Good |
Good |
Good |
Poor |
Test Dataset
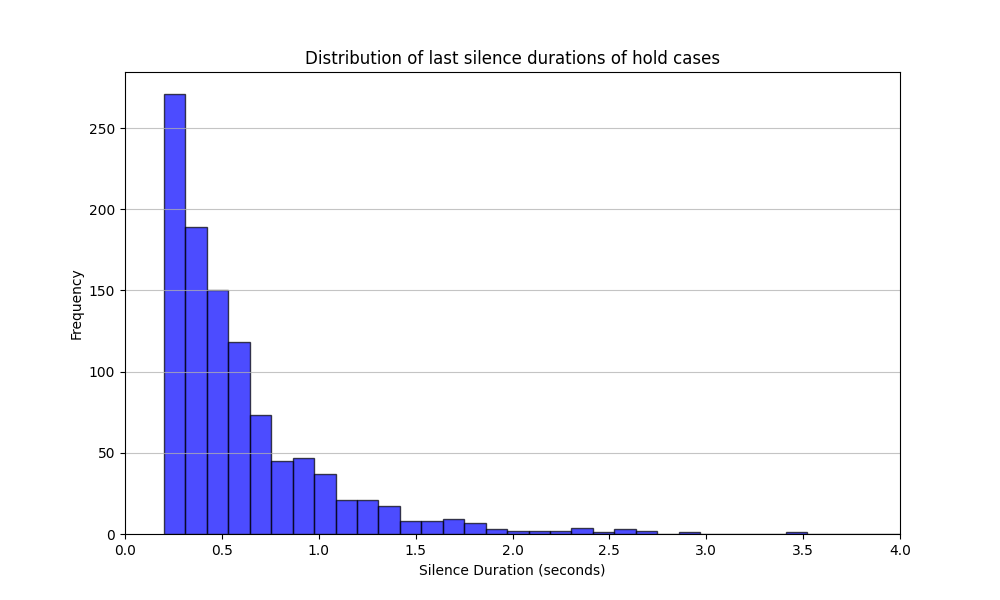
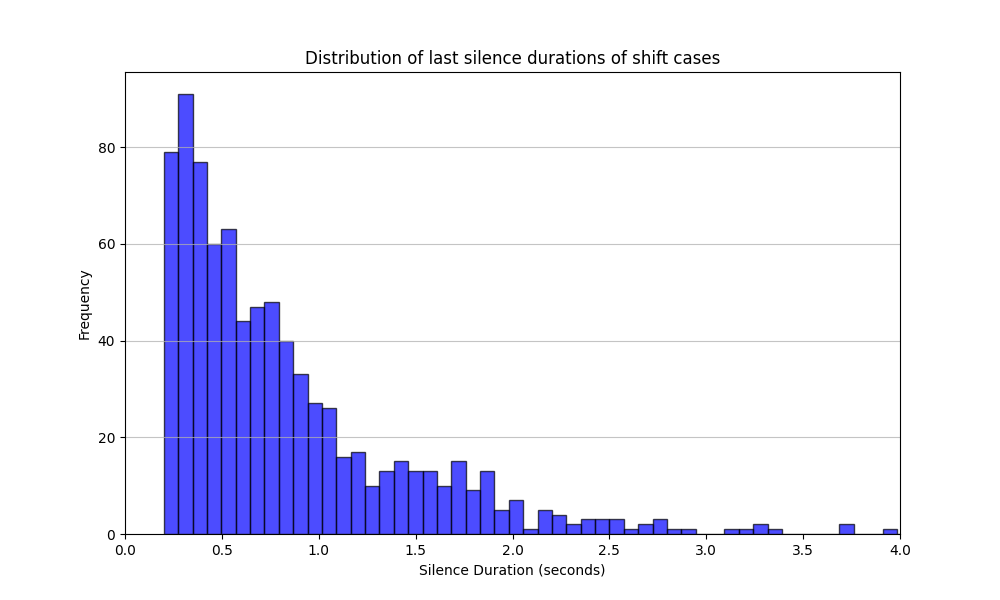
The test dataset was built using real conversational recordings, with manually labeled turn-taking (shift) and hold scenarios (hold). A turn-taking instance marks a point where one speaker hands over the conversation, we will call a shift, while a hold scenario captures cases where the speaker continues after a brief pause, filler words, or unfinished context.
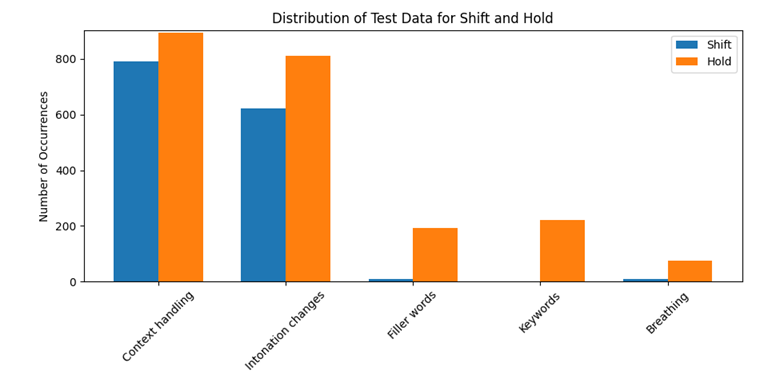
The dataset consists of 1,875 labeled audio samples, including a significant number of labeled shift and hold scenarios. Each audio file is annotated to include the silence at the end of a speaker’s segment – either resulting in a turn shift or a hold. The test data was annotated according to multiple criteria, including context, intonation, filler words (e.g., “um,” “am”), keywords (e.g., “but,” “and”), and breathing patterns.
Below are the statistics on silence duration for each scenario type as well as the distribution of shift and hold cases based on mentioned criteria.
Training Dataset
Our training dataset comprises approximately 2,000 hours of conversational speech, containing around 700,000 speaker turns.
Evaluation: Prediction Quality Metrics
To assess the performance of the turn-taking model, we used a combination of classification metrics and timing-based analysis:
| Metric |
Description |
| TP |
True Positives: Correctly predicted positive class cases |
| TN |
True Negatives: Correctly predicted negative class cases |
| FP |
False Positives: Incorrectly predicted positive class cases |
| FN |
False Negatives: Missed positive class cases |
| Metric |
Formula |
Description |
| Precision |
TP / (TP + FP) |
Proportion of predicted positives that are actually positive |
| Recall |
TP / (TP + FN) |
Proportion of actual positives correctly predicted |
| Specificity |
TN / (TN + FP) |
Proportion of actual negatives correctly predicted |
| Balanced Accuracy |
(Recall + Specificity) / 2 |
Average performance across both classes (positive and negative) |
| F1 Score |
2 × (Precision × Recall) / (Precision + Recall) |
Harmonic mean of Precision and Recall; balances false positives and false negatives |
AUC: The AUC is the area under the ROC curve. A higher AUC value indicates better classification performance, here ROC (receiver operating characteristic) shows the trade-off between the true positive rate and the false positive rate as the decision threshold is varied, for more details on AUC and other metrics read here.
Evaluation: Latency vs. Accuracy tradeoff (MST vs FPR)
We realized that there is a natural tradeoff between the accuracy and latency, i.e. how quickly the system detects a true shift. We can reduce the latency by lowering the threshold, however, it will likely lead to increased false-positive rate (FPR) and unwanted interruptions. On the other hand, we don’t want to wait too long to predict a shift, because the increased latency will result in awkward interaction (see the chart below).
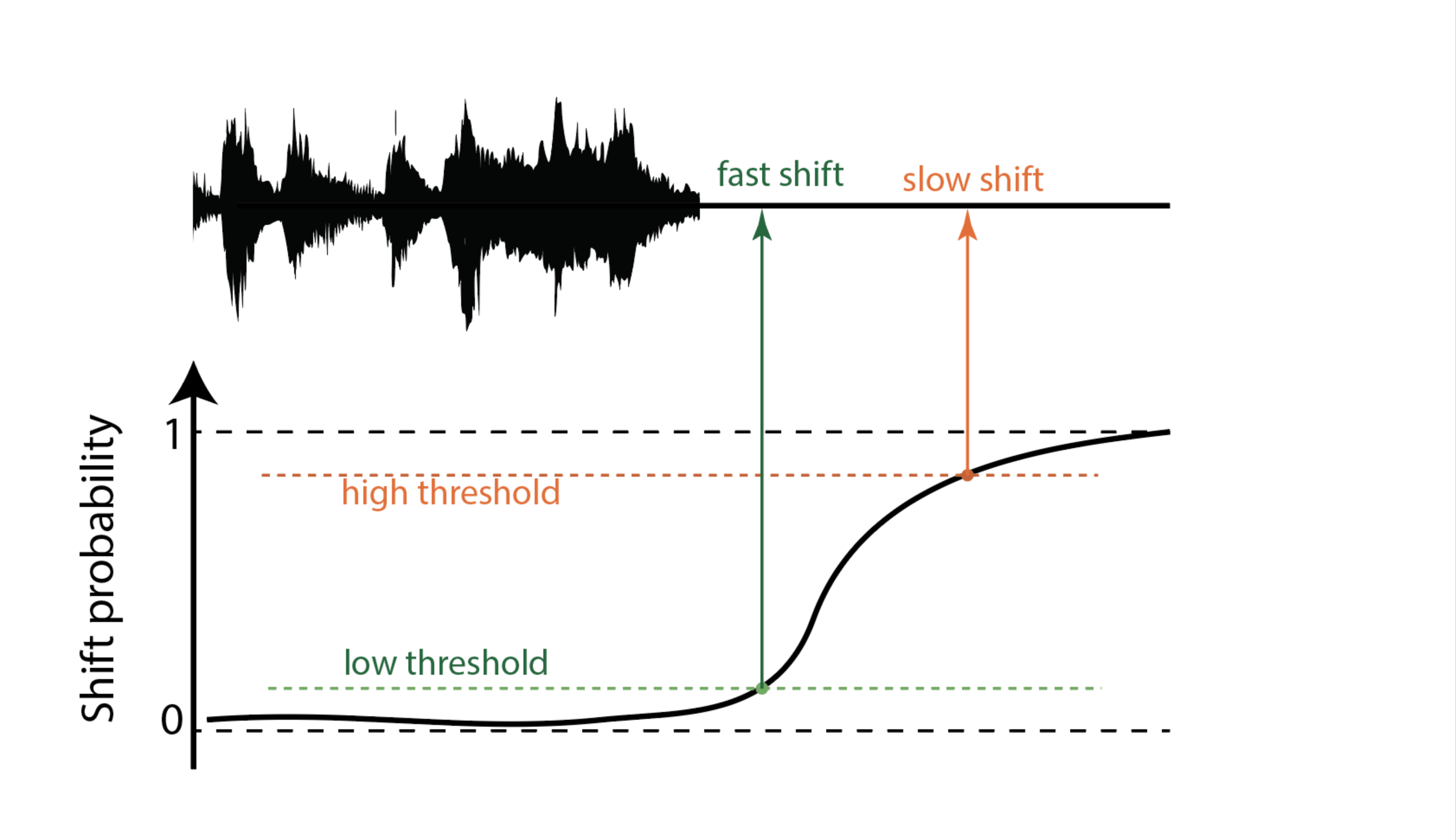
Therefore, the latency to accuracy relationship is important and here we measure TT system’s latency by mean shift time (MST). The shift time is defined as the duration between the onset of silence and the moment of predicting end-of-turn (shift). If the model outputs a confidence score, the end-of-turn prediction can be controlled via a threshold. This makes the threshold an important control lever in the trade-off between reaction speed and prediction accuracy:
- Higher thresholds result in delayed shift predictions, which help reduce false positives (i.e., shift detections during the current speaker hold period which leads to interruption from the bot). However, this increases the mean shift time, making the system slower to respond.
- Lower thresholds lead to faster responses, decreasing mean shift time, but at the cost of increased false positives, potentially causing the bot to interrupt speakers prematurely.
To visualize this trade-off, we plot a chart showing the relationship between mean shift time calculated in end-of-speech cases and false positive (interruption) rate as the threshold varies from 0 to 1. To provide a comparative summary of models, we plot these charts. A lower curve indicates a faster mean response time for the same interruption rate – or, from another perspective, fewer interruptions for the same mean response time. Here you can see the corresponding plots for Krisp TT, SmartTurn v1 and SmartTurn v2. Note that we can’t directly visualize such a chart for the VAD-based TT, as MST vs FPR requires a model that outputs a confidence score, whereas the VAD-based model produces binary outputs (0 or 1). The same limitation applies to AUC-shift computation shown in the table above.
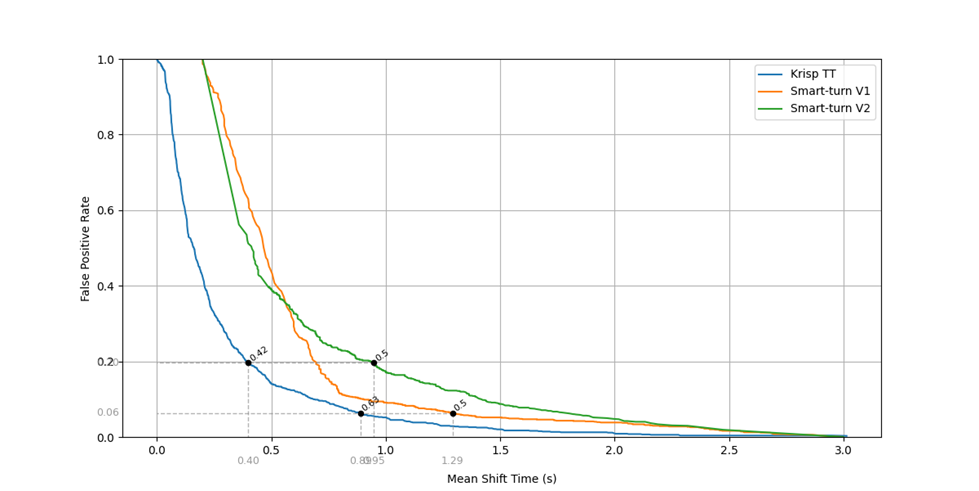
This basically means that the Krisp TT model has considerably faster average response time (0.9 vs. 1.3 seconds at a 0.06 FPR) compared to SmartTurn to produce a true-positive answer.
To summarize the overall latency-accuracy tradeoff, we also compute the area under the MST vs FPR curve. This single scalar score captures the model’s ability to respond quickly while minimizing interruptions across different thresholds. A lower area indicates better performance.
Evaluation Results
| Model |
Balanced Accuracy |
AUC Shift |
F1 Score Shift |
F1 Score Hold |
AUC (MSP vs FPR) |
| Krisp TT |
0.82 |
0.89 |
0.80 |
0.83 |
0.21 |
| VAD based TT |
0.59 |
– |
0.48 |
0.70 |
– |
| SmartTurn V1 |
0.78 |
0.86 |
0.73 |
0.84 |
0.39 |
| SmartTurn V2 |
0.78 |
0.83 |
0.76 |
0.78 |
0.44 |
💡 It’s important to note that the Krisp TT model delivers comparable quality in terms of predictive quality metrics and significantly better quality in terms of latency vs accuracy tradeoff while being 5-10x smaller and optimized to run efficiently on a CPU. The VAD-based turn-taking approach is more lightweight, but it performs significantly worse than dedicated TT models – highlighting the importance of modeling the complex relationships between speech structure, acoustic features, and turn-taking behavior.
Demo
Here’s a simple dialogue showing how Krisp’s Turn-Taking model works in practice. In the demo, you’ll hear intentional utterances, pauses, filler words and interruptions. The response time you observe includes the Turn-Taking model’s speed, plus the latency from the speech-to-text (STT) system and the language model (LLM).
Krisp’s Turn-Taking Model
Krisp’s TT model vs Pipecat’s SmartTurn V2
This demo compares Krisp’s Turn-Taking model with Pipecat’s SmartTurn model (3-second default value, configurable parameter in SmartTurn). To highlight the differences visually, we’ve also overlaid a speech-to-text transcript on the video.
Future Plans
Improved Accuracy in TT
While this initial, audio-based TT model provides balanced accuracy and latency, it is mainly limited to analyzing prosodic and acoustic features, such as changes in intonation, pitch and rhythm. By analyzing linguistic features like the syntactic completion of a sentence we can further improve the accuracy of the TT model.
We plan to build the following features as well:
- Text-based Turn-Taking: This model will use text only input and predict end-of-turn with a custom Neural Network trained for this use case.
- Audio-Text Multimodal (Fusion): This model will use both audio and text inputs to leverage the best from these two modalities and give the highest accuracy end-of-turn prediction.
Early prototypes show promising results, with the multimodal approach outperforming the audio-based turn-taking models noticeably.
Backchannel support
Backchannel detection is another challenge encountered during the development of Voice AI agents. The “backchannel” is the secondary or parallel forms of communication that occur alongside a primary conversation or presentation. It encompasses the responses a listener gives to a speaker to indicate they are paying attention, without taking over the main speaking role.
While interacting with AI agent, in some cases, the user may genuinely want to interrupt – to ask a question or shift the conversation. In others, they might simply be using backchannel cues like “right” or “okay” to signal that they’re actively listening. The core challenge lies distinguishing meaningful interruptions from casual acknowledgments.
Our roadmap includes the release of a reliable dedicated backchannel prediction model.





