Krisp AI Meeting Note Taker
Voice Notes and Memo Recorder
Smarter meetings with transcripts, summaries, and action items
— bot-free recording, noise cancellation, and natural accents.
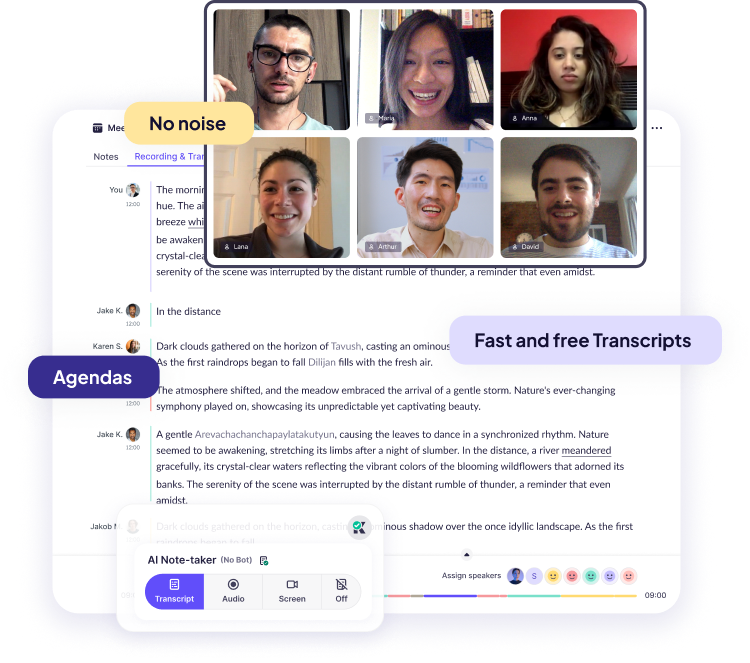
Stay sharp. Stay focused. Let your AI meeting agent handle the rest.
Krisp’s AI meeting assistant silently handles transcripts and recordings.
![]()
#1 AI noise cancellation for any meeting removes noise, echo, and cross-talk.
![]()
AI accent conversion for clearer, more confident communication in every meeting.
![]()
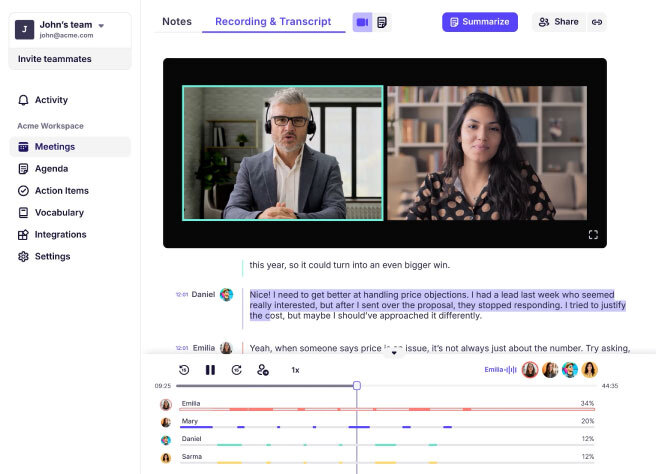
Cut manual work with AI Meeting Minutes, AI Meeting Summary, and CRM updates.
Focus on what matters.
Push notes and action items directly to Salesforce, HubSpot, Slack, and more.
Track tasks from all meetings so nothing falls through the cracks.
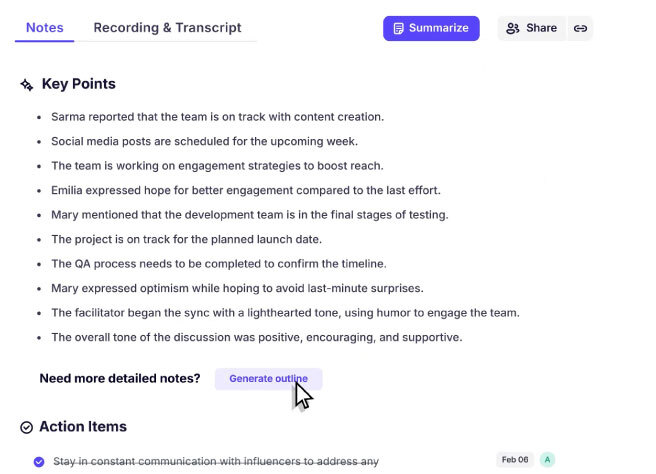
Accurate AI meeting notes to ensure you never miss a detail.
![]()
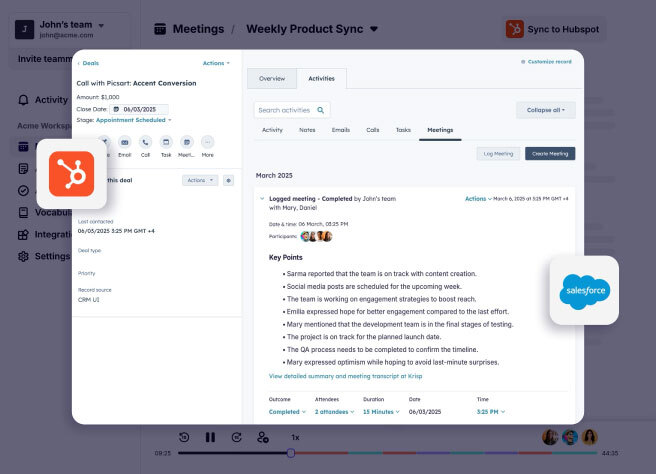
Push notes and action items directly to Salesforce, HubSpot, Slack, and more.
![]()
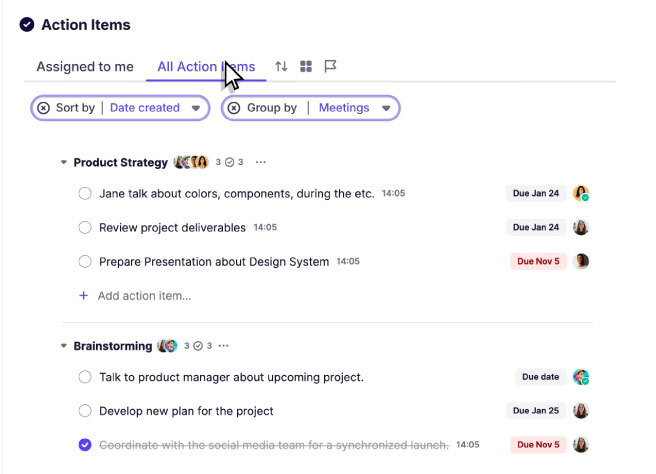
Track tasks from all meetings so nothing falls through the cracks.
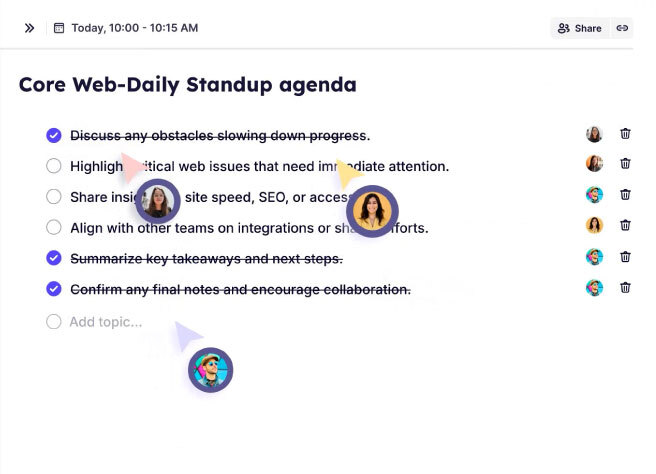
Get ready with the AI meeting agent. Smart agendas and insights before every call.
Get AI suggestions based on previous conversations.
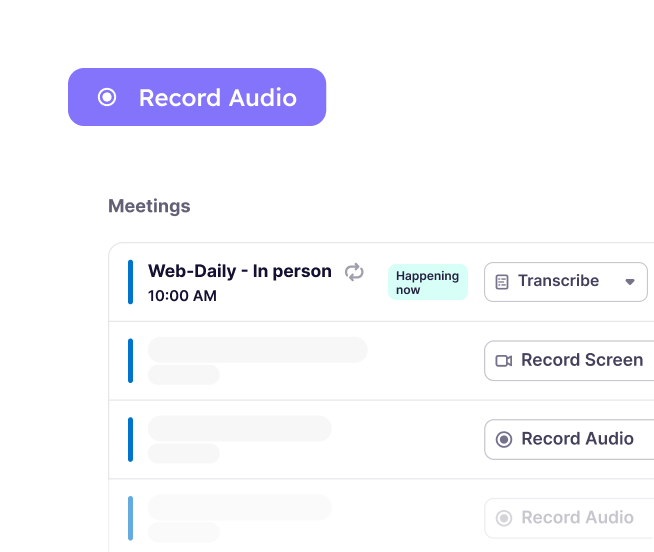
Choose from Transcript-only, Audio or Video modes.
Never miss a meeting, even on busy days.
Get AI suggestions based on previous conversations.
Choose from Transcript-only, Audio or Video modes.
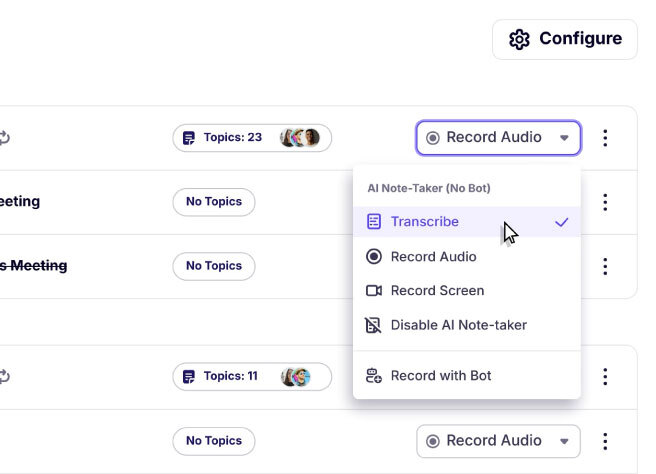
Never miss a meeting, even on busy days.
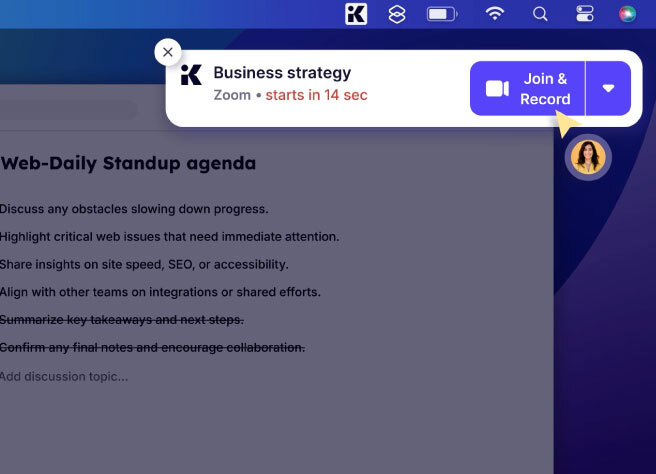
Krisp's noise cancellation transformed our remote meetings.
The new AI assistant features impressed us by streamlining note-taking,
saving time during our 5–6 weekly calls, and boosting overall efficiency.

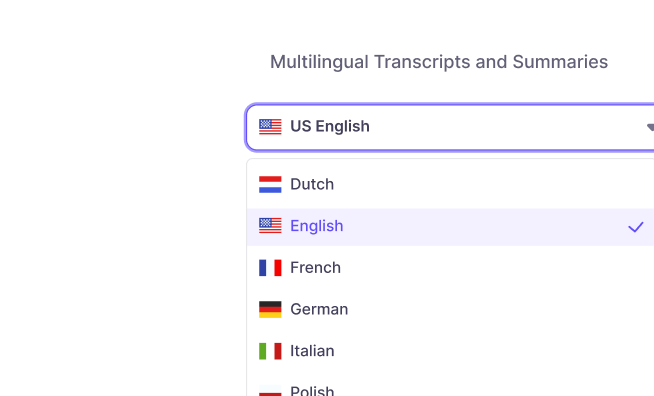
Transcripts and summaries in 16
languages, ensuring seamless
communication across global teams.
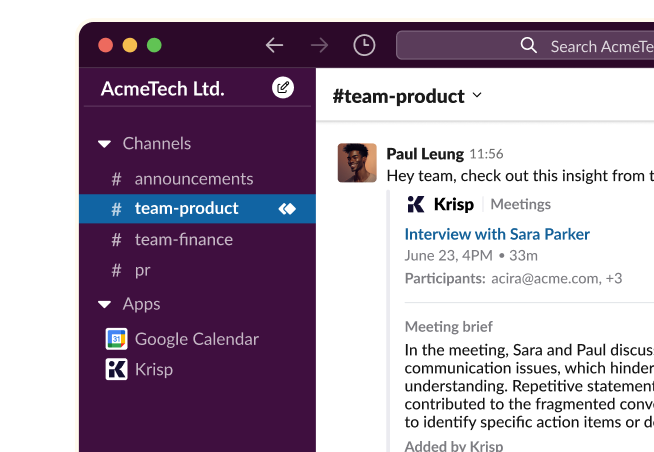
Share notes and summaries via Slack or revisit with an easy-to-navigate timeline.
Not all conversations happen online.
With mobile and desktop support,
easily record and transcribe walk-
and-talks or sit-down meetings..
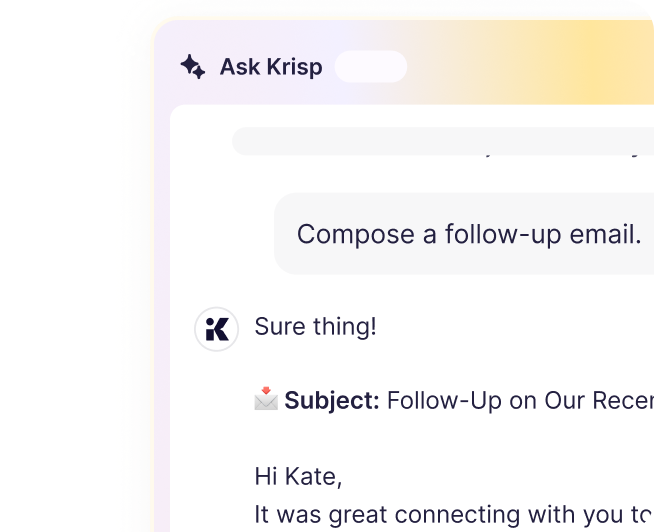
You don’t need to copy and paste transcript to chatGPT if templates we have are not enough. Ask anything right here!
Unlock knowledge buried in team conversations.
From pre-meeting briefs and agendas to follow-ups, everything is organized for quick reference.
With integrations to productivity tools and flexible pricing, Krisp scales with teams of all sizes.
We take security seriously, so you don’t have to worry.
Our enterprise-grade protections keep your information safe, private, and in your control.
From Google Calendar to Zoom, Slack, HubSpot, Salesforce,
and Zapier - Krisp seamlessly fits into your workflow.
Meetings on the go with the Krisp mobile app!

Upload and transcribe your meeting recordings.

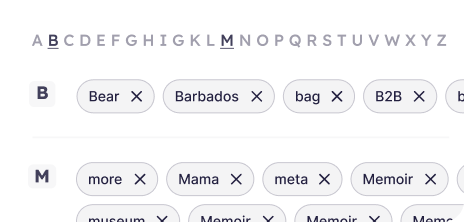
750 workspace-level terms and abbreviations, with industry-specific starter kits to get started easily.
Prefer automated participation?
Enable bots to join meetings when needed


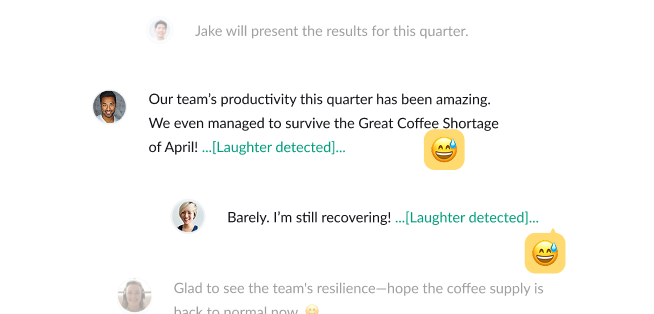
Laughter detection
Because emotions add context to conversations...