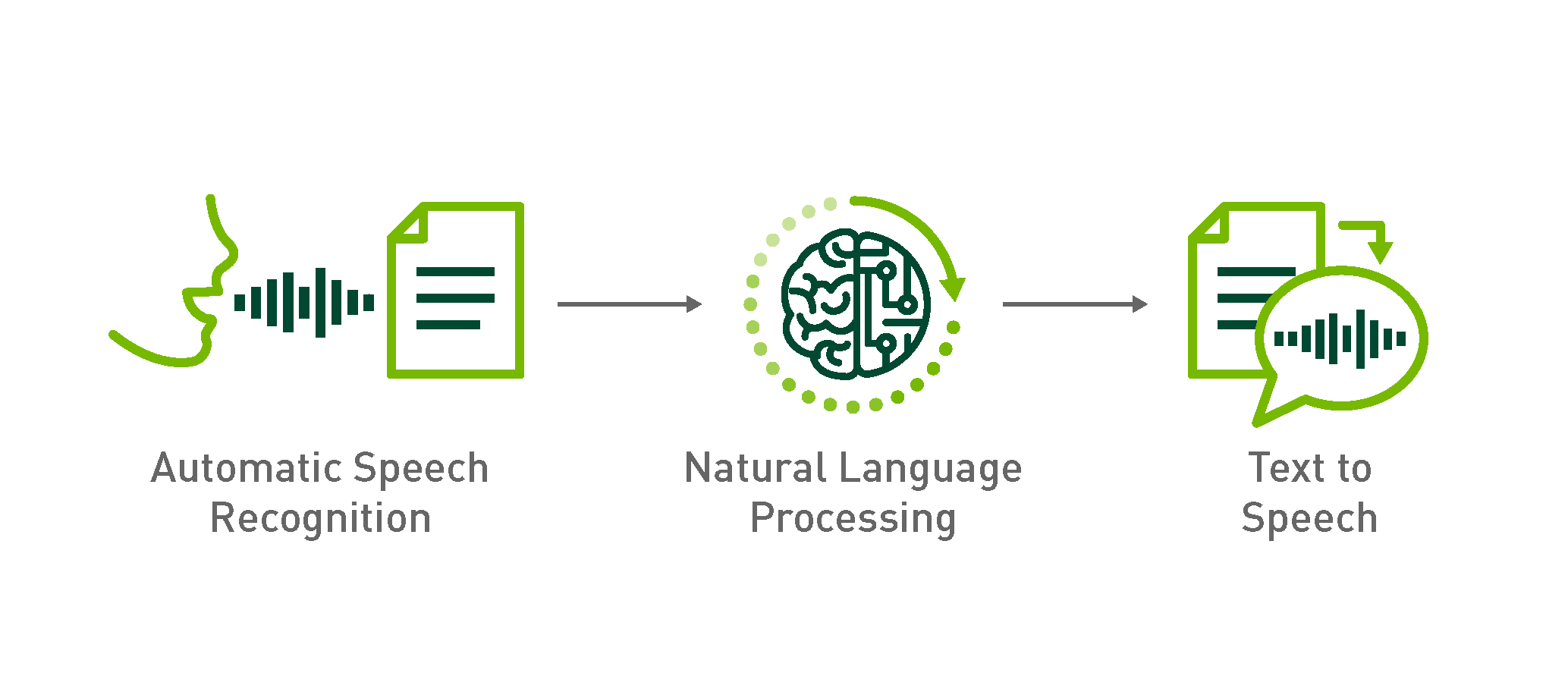
Best Speech-to-Text API Solutions in 2024
Here are some of the top speech-to-text API solutions available in 2024, based on extensive research from reputable sources such as Deepgram, AssemblyAI, and others:
1. Assembly AI
Assembly AI offers a complete voice AI infrastructure layer, now featuring Universal-3 Pro for speech-to-text, the first promptable Speech Language Model that lets developers guide transcription with natural language before processing begins. Rather than correcting output downstream, you shape accuracy upfront by giving the model context about names, terminology, topics, and format.
Assembly AI
Key features
- High-accuracy promptable transcription via natural language instructions.
- Support for multiple languages and dialects, including code switching.
- Real-time and batch processing with speaker role labeling, disfluency capture, and audio event tagging.
Pros
- Context-aware prompting delivers domain-specific accuracy without custom models.
- Supports accurate, low-latency speech-to-text, deep speech understanding, and LLM-powered insights.
- Flexible API integration with comprehensive documentation and developer support.
Cons
- Advanced prompting capabilities may require a learning curve for new users.
- Limited offline processing options.
Use Cases: Suited for medical transcription, contact centers, AI notetakers, conversation intelligence, and media production.
2. Deepgram
Deepgram offers deep learning-based ASR with customizable models, providing high accuracy and fast processing speeds. It integrates seamlessly with various platforms, making it ideal for voice assistants and call analytics.
Deepgram
Key features
- Deep learning-based ASR with customizable models.
- High accuracy and fast processing speeds.
- Integration with various platforms via APIs.
Pros
- Highly scalable for large-scale applications.
- Offers real-time and batch processing options.
- Supports multiple languages and dialects.
Cons
- Customization may require technical expertise.
- Premium features can be costly.
Use Cases: Ideal for voice assistants, transcription, and call analytics.
3. Speechmatics
Speechmatics is renowned for its universal speech recognition technology, offering high accuracy across diverse accents and dialects. It is particularly useful for enterprise applications, providing scalable solutions for various industries.
Speechmatics
Key features
- Universal speech recognition with high accuracy.
- Support for diverse accents and dialects.
- Scalable solutions for enterprise applications.
Pros
- Highly accurate transcription across various dialects.
- Strong enterprise support and scalability.
- Continuous improvements and updates.
Cons
- Setup can be complex for new users.
- Higher cost for extensive usage.
Use Cases: Useful for broadcast media, telecommunication, and transcription services.
4. Rev AI
Rev AI stands out with its industry-leading accuracy, offering human-reviewed options for even higher precision. It supports real-time and asynchronous transcription, making it perfect for media production and legal sectors.
Rev AI
Key features
- Industry-leading accuracy with human-reviewed options.
- Real-time and asynchronous transcription.
- Easy integration with SDKs and APIs.
Pros
- Highly accurate transcriptions with human review.
- Versatile integration options for various platforms.
- Strong reputation in the industry.
Cons
- Human-reviewed transcriptions can be more expensive.
- Limited free tier options.
Use Cases: Perfect for media production, legal, and education sectors.
5. Whisper
Whisper, developed by OpenAI, is a cutting-edge speech recognition technology offering high accuracy and robust performance. It supports multiple languages and is ideal for developers seeking open-source solutions.
Whisper
Key features
- OpenAI’s cutting-edge speech recognition technology.
- High accuracy and robust performance.
- Support for multiple languages.
Pros
- Open-source and customizable.
- Strong performance across various languages.
- Free to use with extensive documentation.
Cons
- May require fine-tuning for specific applications.
- Limited support compared to commercial solutions.
Use Cases: Suitable for developers seeking open-source solutions for diverse applications.
6. Symbl
Symbl offers advanced conversational intelligence with contextual understanding, providing real-time transcription and analysis. It integrates well with communication platforms, making it ideal for customer service and team collaboration.
Symbl
Key features
- Conversational intelligence with contextual understanding.
- Real-time transcription and analysis.
- Integration with communication platforms.
Pros
- Advanced contextual understanding enhances transcription accuracy.
- Seamless integration with various communication tools.
- Offers real-time insights and analytics.
Cons
- Can be complex to integrate without technical expertise.
- Some features are available only in premium plans.
Use Cases: Ideal for customer service, sales, and team collaboration tools.
Krisp: The Ultimate Transcription Solution for Call Centers
Krisp is a versatile and reliable transcription software designed to enhance call center operations and improve customer service.
-
Superior Transcription Accuracy
- 96% Accuracy: Leveraging cutting-edge AI, Krisp ensures high-quality transcriptions even in noisy environments, boasting a Word Error Rate (WER) of only 4%.
On-Device Processing
- Enhanced Security: Krisp’s desktop app processes transcriptions and noise cancellation directly on your device, ensuring sensitive information remains secure and compliant with stringent security standards.
Unmatched Privacy
- Real-Time Redaction: Ensures the utmost privacy by redacting Personally Identifiable Information (PII) and Payment Card Information (PCI) in real-time.
- Private Cloud Storage: Stores transcripts in a private cloud owned by customers, with write-only access, ensuring complete control over data.
Centralized Solution Across All Platforms
- Cost Optimization: By centralizing call transcriptions across all platforms, Krisp CCT optimizes costs and simplifies data management.
- Streamlined Operations: Eliminates the need for multiple transcription services, making data handling more efficient.
No Additional Integrations Required
- Effortless Integration: Krisp’s plug-and-play setup integrates seamlessly with major Contact Center as a Service (CCaaS) and Unified Communications as a Service (UCaaS) platforms.
- Operational Efficiency: Requires no additional configurations, ensuring smooth and secure operations from the start.
| Use Case |
Description |
| Enhancing Call Center Efficiency |
Boost your BPO’s efficiency by ensuring quality control of customer interactions, enabling targeted training and coaching sessions, refining sales strategies, and improving call center metrics for an enhanced operation. |
| Better Compliance and Record-Keeping |
Maintain regulatory compliance and adhere to industry standards with Krisp CCT, which provides a searchable record of all customer interactions. This can support your compliance efforts and offer valuable information for dispute resolution. |
| Enabling Customer Intel Gathering |
Streamline customer research and analysis, identify actionable customer insights, and collect feature requests to better understand and serve your customers. |
| Fortifying Fraud Detection |
Identify fraudulent patterns in customer interactions, mitigate data breaches, and enhance fraud prevention strategies to protect your business and customers with Krisp CCT. |
|
|