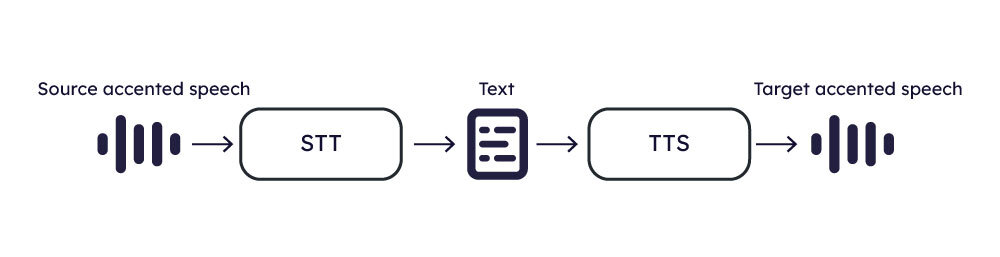
In this article, we dive deep into a new disruptive technology called AI Accent Conversion, which in real-time translates a speaker’s accent to the listener’s natively understood accent, using AI.
Accent refers to the distinctive way in which a group of people pronounce words, influenced by their region, country, or social background. In broad terms, English accents can be categorized into major groups such as British, American, Australian, South African, and Indian among others.
Accents can often be a barrier to communication, affecting the clarity and comprehension of speech. Differences in pronunciation, intonation, and rhythm can lead to misunderstandings.
While the importance of this topic goes beyond call centers, our primary focus is this industry.
Offshore expansion and accented speech in call centers
The call center industry in the United States has experienced substantial growth, with a noticeable surge in the creation of new jobs from 2020-onward, both on-shore and globally.
In 2021, many US based call centers expanded their footprints thanks to the pandemic-fueled adoption of remote work, but growth slowed substantially in 2022. Inflated salaries and limited resources drove call centers to deepen their offshore operations, both in existing and new geographies.
There are several strong incentives for businesses to expand call centers operations to off-shore locations, including:
Cost savings: Labor costs in offshore locations such as India, the Philippines, and Eastern Europe are up to 70% lower than in the United States.
Access to diverse talent pools: Offshoring enables access to a diverse talent pool, often with multilingual capabilities, facilitating a more comprehensive customer support service.
24/7 coverage: Time zone differences allow for 24/7 coverage, enhancing operational continuity.
However, offshore operations come with a cost. One major challenge offshore call centers face is decreased language comprehension. Accents, varying fluency levels, cultural nuances and inherent biases lead to misunderstandings and frustration among customers.
According to Reuters, as many as 65% of customers have cited difficulties in understanding offshore agents due to language-related issues. Over a third of consumers say working with US-based agents is most important to them when contacting an organization.
Ways accents create challenges in call centers
While the world celebrates global and diverse workforces at large, research shows that misalignment of native language backgrounds between speakers leads to a lack of comprehension and inefficient communication.
Longer calls: Thick accents contribute to comprehension difficulties, causing higher average handle time (AHT) and also lower first call resolutions (FCR). According to ContactBabel’s “2024 US Contact Center Decision Maker’s Guide” the cost of mishearing and repetition per year for a 250-seat contact center exceeds $155,000 per year.
Decreased customer satisfaction: Language barriers are among the primary contributors to lower customer satisfaction scores within off-shore call centers. According to ContactBabel, 35% of consumers say working with US-based call center agents is most important to them when contacting an organization.
High agent attrition rates: Decreased customer satisfaction and increased escalations create high stress for agents, in turn decreasing agent morale. The result is higher employee turnover rates and short-term disability claims. In 2023, US contact centers saw an average annual agent attrition rate of 31%, according to The US Contact Center Decision Makers’ Guide to Agent Engagement and Empowerment.
Increased onboarding costs: The need for specialized training programs to address language and cultural nuances further adds to onboarding costs.
Limited talent pool: Finding individuals who meet the required linguistic criteria within the available talent pool is challenging. The competitive demand for specialized language skills leads to increased recruitment costs.
How do call centers mitigate accent challenges today?
Training
Accent neutralization training is used as a solution to improve communication clarity in these environments. Call Centers invest in weeks-long accent neutralization training as part of agent onboarding and ongoing improvement. Depending on geography, duration, and training method, training costs can run $500-$1500 per agent during onboarding. The effectiveness of these training programs can be limited due to the inherent challenges in altering long-established accent habits. So, call centers may find it necessary to temporarily remove agents from their operational roles for further retraining, incurring additional costs in the process.
Limited geography for expansion
Call centers limit their site selection to regions and countries where accents of the available talent pool is considered to be more neutral to the customer’s native language, sacrificing locations that would be more cost-effective.
Enter AI-Powered Accent Conversion
Recent advancements in Artificial Intelligence have introduced new accent conversion technology. This technology leverages AI to translate source accents to targets accent in real-time, with the click of a button. While the technologies in production don’t support multiple accents in parallel, over time this will be solved as well.
State of the Art AI Accent Conversion Demo
Below is the evolution of Krisp’s AI Accent Conversion technology over the past 2 years.
Version
Demo
v0.1 First model
v0.2 A bit more natural sound
v0.3 A bit more natural sound
v0.4 Improved voice
v0.5 Improved intonation transfer
This innovation is revolutionary for call centers as it eliminates the need for difficult and expensive training and increases the talent pool worldwide, providing immediate scalability for offshore operations.
It’s also highly convenient for agents and reduces the cognitive load and stress they have today. This translates to decreased short-term disability claims and attrition rates, and overall improved agent experience.
Deploying AI Accent Conversion in the call center
There are various ways AI Accent Conversion can be integrated into a call center’s tech stack.
It can be embedded into a call center’s existing CX software (e.g. CCaaS and UCaaS) or installed as a separate application on the agent’s machine (e.g. Krisp).
Currently, there are no CX solutions in market with accent conversion capabilities, leaving the latter as the only possible path forward for call centers looking to leverage this technology today.
Applications like Krisp have accent conversion built in their offerings.
These applications are on-device, meaning they sit locally on the agent’s machine. They support all CX software platforms out of the box since they are installed as a virtual microphone and speaker.
AI runs on an agent’s device so there is no additional load on the network.
The deployment and management can be done remotely, and at scale, from the admin dashboard.
Challenges of building AI Accent Conversion technology
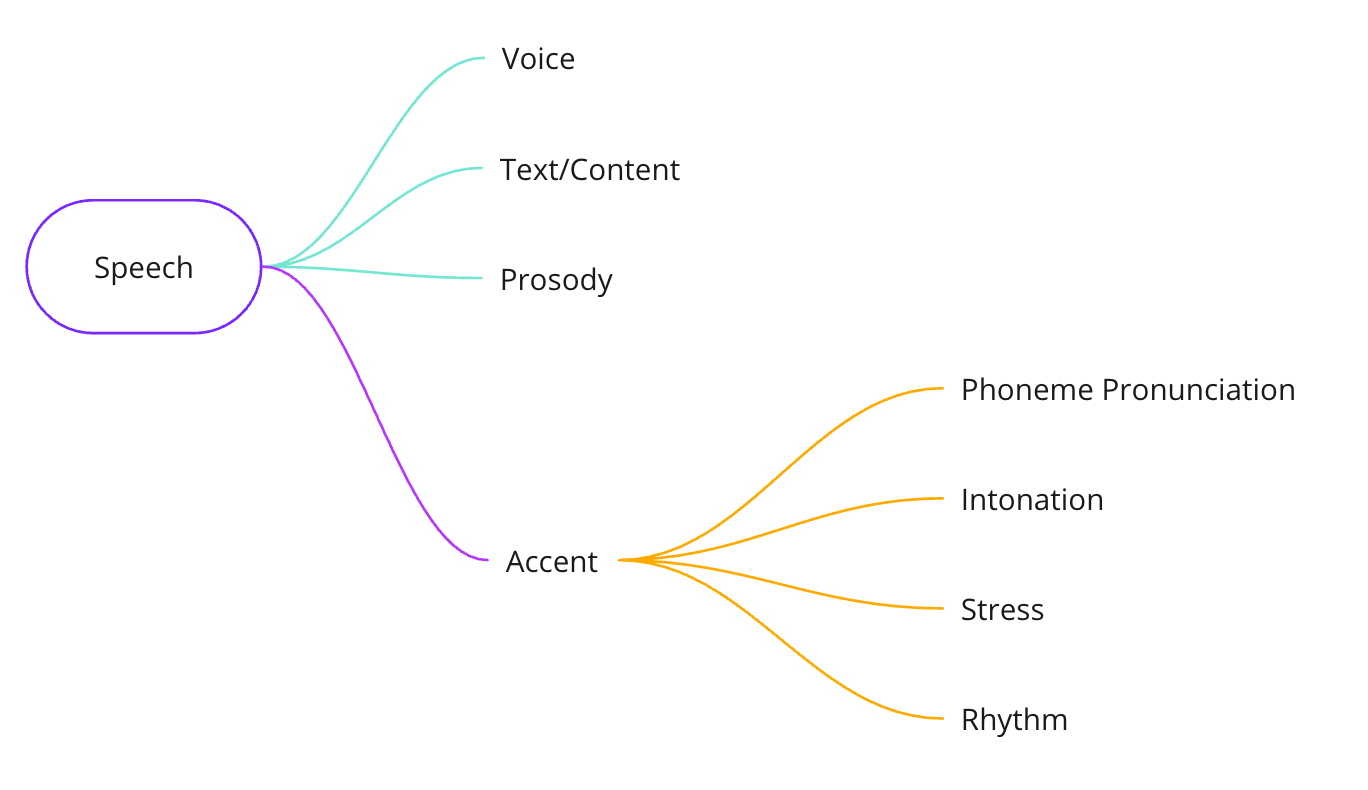
At a fundamental level, speech can be divided into 4 parts: voice, text, prosody and accent.
Accents can be divided into 4 parts as well – phoneme, intonation, stress and rhythm.
In order to convert or translate an accent, three of these parts must be changed – phoneme pronunciation, intonation, and stress. Doing this in real-time is an extremely difficult technical problem.
While there are numerous technical challenges in building this technology, we will focus on eight majors.
Data Collection
Speech Synthesis
Low Latency
Background Noises and Voices
Acoustic Conditions
Maintaining Correct Intonation
Maintaining Speaker’s Voice
Wrong Pronunciations
Let’s discuss them individually.
1) Data collection
Collecting accented speech data is a tough process. The data must be highly representative of different dialects spoken in the source language. Also, it should cover various voices, age groups, speaking rates, prosody, and emotion variations. For call centers, it is preferable to have natural conversational speech samples with rich vocabulary targeted for the use case.
There are two options: buy ready data or record and capture the data in-house. In practice, both can be done in parallel.
An ideal dataset would consist of thousands of hours of speech where source accent utterance is mapped to each target accent utterance and aligned with it accurately.
However, getting precise alignment is exceedingly challenging due to variations in the duration of phoneme pronunciations. Nonetheless, improved alignment accuracy contributes to superior results.
2) Speech synthesis
The speech synthesis part of the model, which is sometimes referred to as the vocoder algorithm in research, should produce a high-quality, natural-sounding speech waveform. It is expected to sound closer to the target accent, have high intelligibility, be low-latency, convey natural emotions and intonation, be robust against noise and background voices, and be compatible with various acoustic environments.
3) Low latency
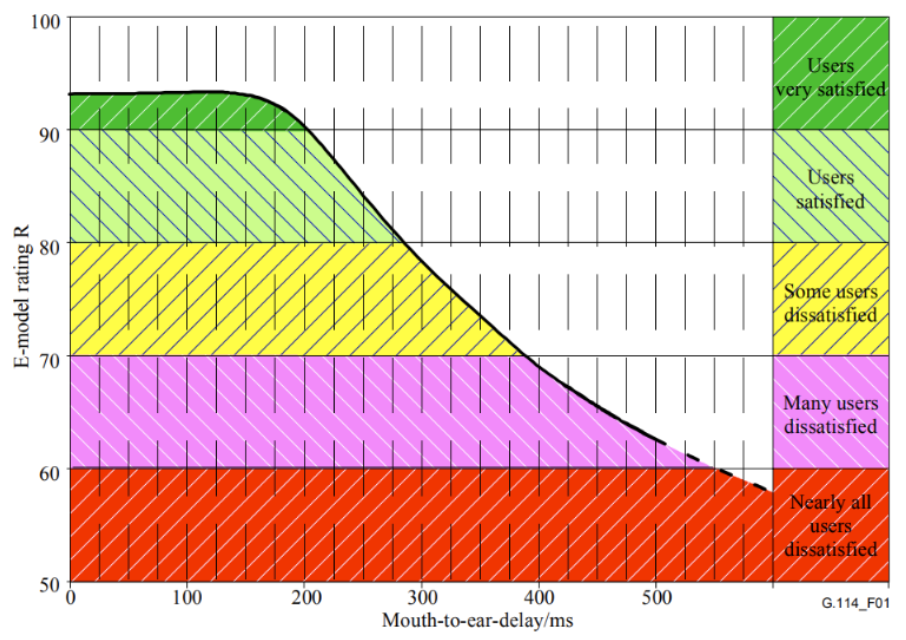
As studies by the International Telecommunication Union show (G.114 recommendation), speech transmission maintains acceptable quality during real-time communication if the one-way delay is less than approximately 300 ms. Therefore, the latency of the end-to-end accent conversion system should be within that range to ensure it does not impact the quality of real-time conversation.
There are two ways to run this technology: locally or in the cloud. While both have theoretical advantages, in practice, more systems with similar characteristics (e.g. AI-powered noise cancellation, voice conversion, etc.) have been successfully deployed locally. This is mostly due to hard requirements around latency and scale.
To be able to run locally, the end-to-end neural network must be small and highly optimized, which requires significant engineering resources.
4) Background noise and voices
Having a sophisticated noise cancellation system is crucial for this Voice AI technology. Otherwise, the speech synthesizing model will generate unwanted artifacts.
Not only should it eliminate the input background noise but also the input background voices. Any sound that is not the speaker’s voice must be suppressed.
This is especially important in call center environments where multiple agents sit in close proximity to each other, serving multiple customers simultaneously over the phone.
Detecting and filtering out other human voices is a very difficult problem. As of this writing, to our knowledge, there is only one system doing it properly today – Krisp’s AI Noise Cancellation technology.
5) Acoustic conditions
Acoustic conditions differ for call center agents. The sheer volume of combinations of device microphones and room setups (accountable for room echo) makes it very difficult to design a robust system against such input variations.
6) Maintaining the speaker’s intonation
Not transferring the speaker’s intonation in the generated speech will result in a robotic speech that sounds worse than the original.
Krisp addressed this issue by developing an algorithm capturing input speaker’s intonation details in real-time and leveraging this information in the synthesized speech. Solving this challenging problem allowed us to increase the naturalness of the generated speech.
7) Maintaining the speaker’s voice
It is desirable to maintain the speaker’s vocal characteristics (e.g., formants, timbre) while generating output speech. This is a major challenge and one potential solution is designing the speech synthesis component so that it generates speech conditioned on the input speaker’s voice ‘fingerprint’ – a special vector encoding a unique acoustic representation of an individual’s voice.
8) Wrong pronunciations
Mispronounced words can be difficult to correct in real-time, as the general setup would require separate automatic speech recognition and language modeling blocks, which introduce significant algorithmic delays and fail to meet the low latency criterion.
3 technical approaches to AI Accent Conversion
Approach 1: Speech → STT → Speech
One approach to accent conversion involves applying Speech-to-Text (STT) to the input speech and subsequently utilizing Text-to-Speech (TTS) algorithms to synthesize the target speech.
This approach is relatively straightforward and involves common technologies like STT and TTS, making it conceptually simple to implement.
STT and TTS are well-established, with existing solutions and tools readily available.
Integration into the algorithm can leverage these technologies effectively. These represent the strengths of the method, yet it is not without its drawbacks. There are 3 of them:
The difficulty of having accent-robust STT with a very low word error rate.
The TTS algorithm must possess capabilities to manage emotions, intonation, and speaking rate, which should come from original accented input and produce speech that sounds natural.
Algorithmic delay within the STT plus TTS pipeline may fall short of meeting the demands of real-time communication.
Approach 2: Speech → Phoneme → Speech
First, let’s define what a phoneme is. A phoneme is the smallest unit of sound in a language that can distinguish words from each other. It is an abstract concept used in linguistics to understand how language sounds function to encode meaning. Different languages have different sets of phonemes; the number of phonemes in a language can vary widely, from as few as 11 to over 100. Phonemes themselves do not have inherent meaning but work within the system of a language to create meaningful distinctions between words. For example, the English phonemes /p/ and /b/ differentiate the words “pat” and “bat.”
The objective is to first map the source speech to a phonetic representation, then map the result to the target speech’s phonetic representation (content), and then synthesize the target speech from it.
This approach enables the achievement of comparatively smaller delays than Approach 1. However, it faces the challenge of generating natural-sounding speech output, and reliance solely on phoneme information is insufficient for accurately reconstructing the target speech. To address this issue, the model should also extract additional features such as speaking rate, emotions, loudness, and vocal characteristics. These features should then be integrated with the target speech content to synthesize the target speech based on these attributes.
Approach 3: Speech → Speech
Another approach is to create parallel data using deep learning or digital signal processing techniques. This entails generating a native target-accent sounding output for each accented speech input, maintaining consistent emotions, naturalness, and vocal characteristics, and achieving an ideal frame-by-frame alignment with the input data.
If high-quality parallel data are available, the accent conversion model can be implemented as a single neural network algorithm trained to directly map input accented speech to target native speech.
The biggest challenge of this approach is obtaining high-quality parallel data.The quality of the final model directly depends on the quality of parallel data.
Another drawback is the lack of integrated explicit control over speech characteristics, such as intonation, voice, or loudness. Without this control, the model may fail to accurately learn these important aspects.
How to measure the quality AI Accent Conversion output
High-quality output of accent conversion technology should:
Be intelligible
Have little or no accentedness (the degree of deviation from the native accent)
Sound natural
To evaluate these quality features, we use the following objective metrics:
Word Error Rate (WER)
Phoneme Error Rate (PER)
Naturalness prediction
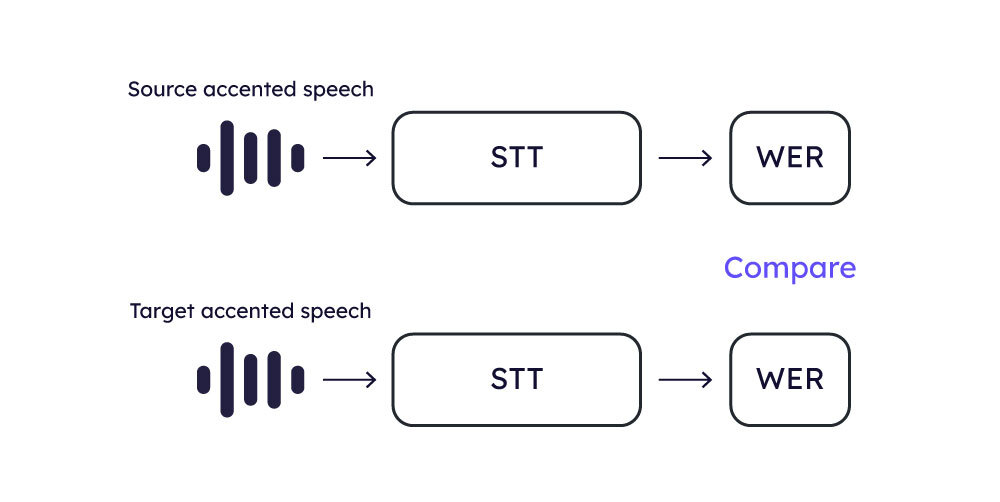
Word Error Rate (WER)
WER is a crucial metric used to assess STT systems’ accuracy. It quantifies the word level errors of predicted transcription compared to a reference transcription.
To compute WER we use a high-quality STT system on generated speech from test audios that come with predefined transcripts.
The evaluation process is the following:
The test set is processed through the candidate accent conersion model to obtain the converted speech samples.
These converted speech samples are then fed into the STT system to generate the predicted transcriptions.
WER is calculated using the predicted and the reference texts.
The assumption in this methodology is that a model demonstrating better intelligibility will have a lower WER score.
Phoneme Error Rate (PER)
The AL model may retain some aspects of the original accent in the converted speech, notably in the pronunciation of phonemes. Given that state-of-the-art STT systems are designed to be robust to various accents, they might still achieve low WER scores even when the speech exhibits accented characteristics.
To identify phonetic mistakes, we employ the Phoneme Error Rate (PER) as a more suitable metric than WER. PER is calculated in a manner similar to WER, focusing on phoneme errors in the transcription, rather than word-level errors.
The test set is processed by the candidate AL model to produce the converted speech samples.
These converted speech samples are fed into the phoneme recognition system to obtain the predicted phonetic transcriptions.
PER is calculated using predicted and reference phonetic transcriptions.
This method addresses the phonetic precision of the AL model to a certain extent.
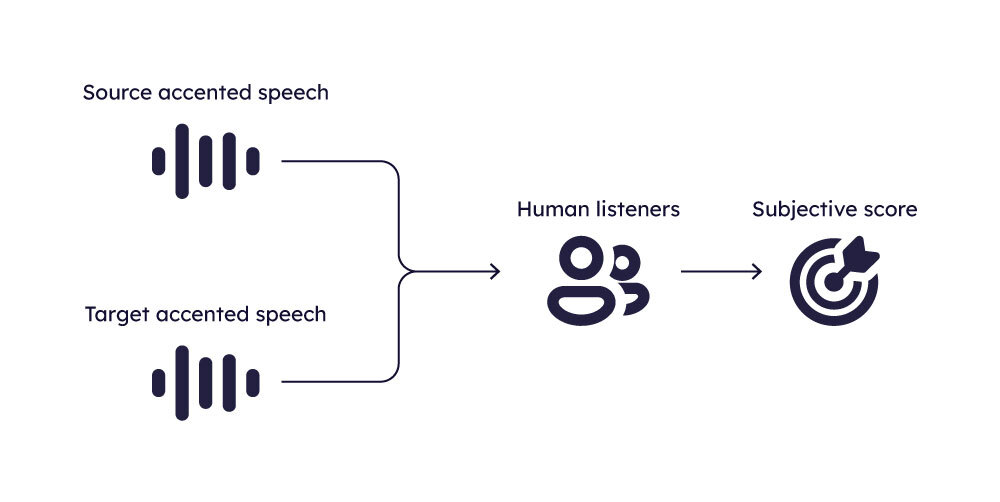
Naturalness Prediction
To assess the naturalness of generated speech, one common method involves conducting subjective listening tests. In these tests, listeners are asked to rate the speech samples on a 5-point scale, where 1 denotes very robotic speech and 5 denotes highly natural speech.
The average of these ratings, known as the Mean Opinion Score (MOS), serves as the naturalness score for the given sample.
In addition to subjective evaluations, obtaining an objective measure of speech naturalness is also feasible. It is a distinct research direction—predicting the naturalness of generated speech using AI. Models in this domain are developed using large datasets comprised of subjective listening assessments of the naturalness of generated speech (obtained from various speech-generating systems like text-to-speech, voice conversion, etc).
These models are designed to predict the MOS score for a speech sample based on its characteristics. Developing such models is a great challenge and remains an active area of research. Therefore, one should be careful when using these models to predict naturalness. Notable examples include the self-supervised learned MOS predictor and NISQA, which represent significant advances in this field.
In addition to objective metrics mentioned above, we conduct subjective listening tests and calculate objective scores using MOS predictors. We also manually examine the quality of these objective assessments. This approach enables a thorough analysis of the naturalness of our AL models, ensuring a well-rounded evaluation of their performance.
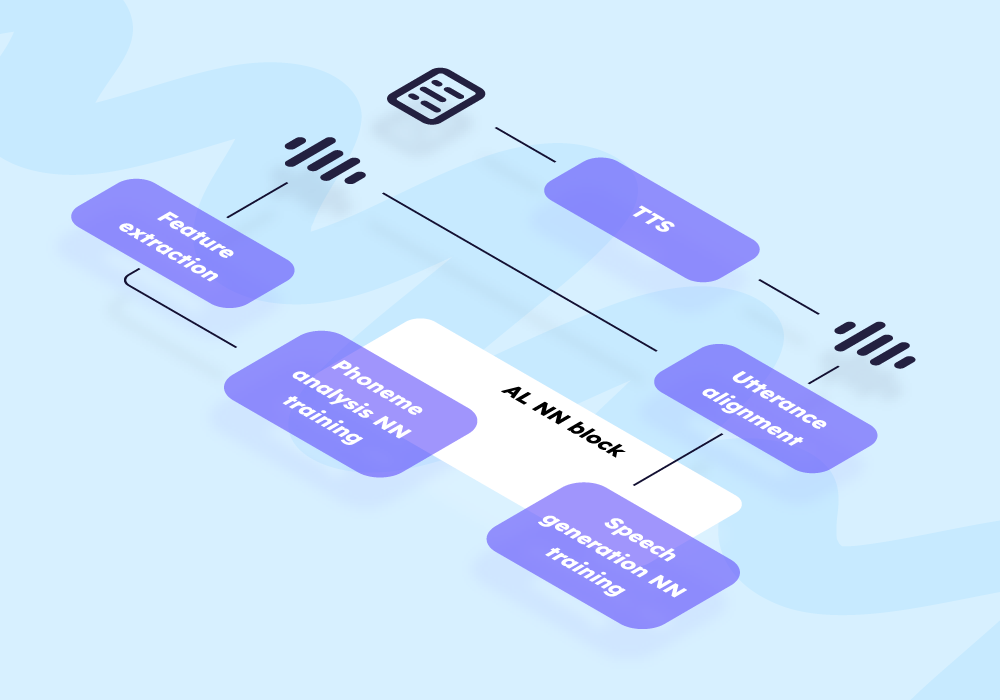
AI Accent Conversion model training and inference
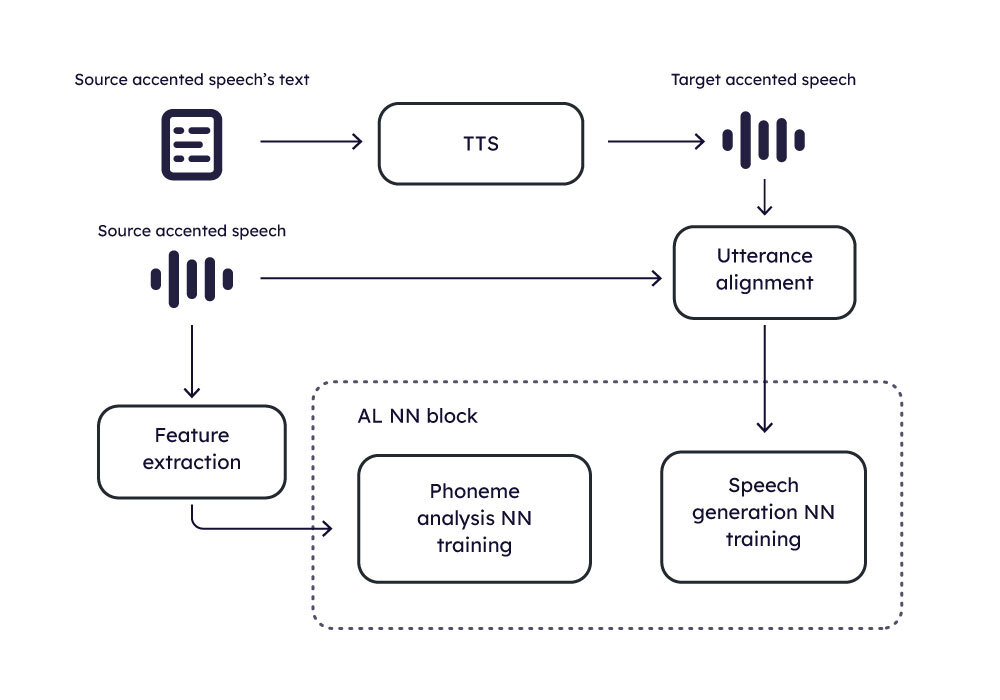
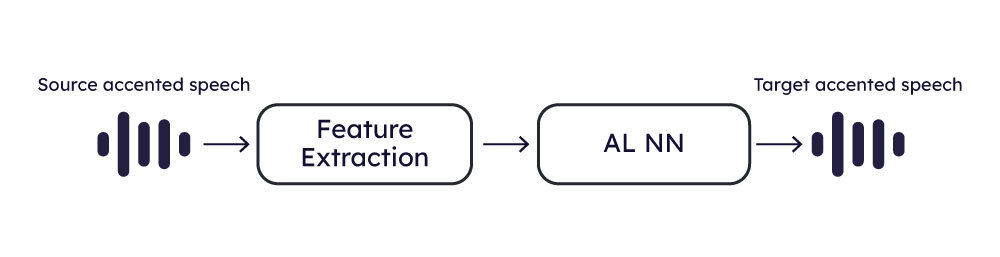
The following diagrams show how the training and inference are organized.
AI Training
AI Inference
Closing
In navigating the complexities of global call center operations, AI Accent Conversion technology is a disruptive innovation, primed to bridge language barriers and elevate customer service while expanding talent pools, reducing costs, and revolutionizing CX.