If you’ve ever been on a global call where someone shares a customer name, a budget number, or a key next step—and half the room asks, “Sorry, can you repeat that?”—you’ve seen how fast momentum can break. It’s rarely about “bad English.”
More often, it’s a mix of accent variation, fast turn-taking, and messy audio that makes certain sounds, names, and numbers hard to catch in real time.
That’s where Accent AI comes in: a growing set of voice-AI technologies focused on reducing accent-related friction in communication. Alongside speech enhancement (noise/echo removal), automatic speech recognition (ASR), and text-to-speech (TTS), Accent AI is evolving toward something especially powerful: AI Accent Conversion for better understanding—technology that can adapt incoming speech to the listener’s preferred accent in real time, helping people understand each other more reliably during live conversations, not just in recordings or transcripts.
In other words, Accent AI is the broader category, and listener mode AI Accent Conversion is one of its newest breakthroughs—designed to make real-time communication smoother, so teams spend less time decoding speech and more time deciding and acting.
In this guide, we’ll define the field, explain why misunderstandings happen (and why live conversations amplify them), break down how real-time accent tech works, map the product landscape, and show how Krisp applies Real Time AI Accent Conversion across everyday communication—meetings, calls, and beyond.
What is Accent AI? A practical definition
If you’re searching what is accent AI, the simplest way to think about it is this: as voice AI matured—through better speech representations and big leaps in ASR (speech recognition) and TTS (text-to-speech)—it became possible to model how people pronounce the same language differently. Those differences are what we call accent variation, and they can affect how easily speech is understood in real time.
Accent AI refers to AI techniques that model accent variation to analyze, generate, or improve the understandability of speech. In other words, it’s not one single product type—it’s a family of approaches that can be used for different goals, from insights to content creation to clearer live conversations.
Where Accent AI shows up most often:
- Measuring/describing accents (analysis, coaching, analytics): tools that classify accent patterns or provide feedback (e.g., “what accent do I have?”), sometimes used in training or quality monitoring.
- Generating accents (accented TTS, voice styling): systems that produce speech in a chosen accent or style for narration, localization, or content workflows.
- Improving real-time understandability: solutions designed to reduce misunderstandings in live communication—especially where people frequently ask for repeats or mishear names and numbers.
What Accent AI is not (boundaries)
Accent AI is often confused with adjacent technologies, so it helps to draw clear lines.
- Accent conversion vs translation: translation changes the language (English to Italian, for example), while accent conversion changes speech characteristics within the same language (how sounds are produced, not what words mean).
- Accent conversion vs voice cloning: voice cloning aims to replicate a specific person’s identity or voiceprint; Accent AI for meetings should focus on clarity and intelligibility, not impersonation.
It’s also not grammar correction, not a substitute for speaking lessons, and it shouldn’t be framed as “accent removal.” In professional settings, the defensible goal is reducing friction—fewer “can you repeat that?” moments—while respecting that accents are part of identity.
Why accent misunderstandings happen in real conversations

If you’ve ever dealt with hard to understand accents on calls or online meetings, it’s rarely a single issue. Most breakdowns come from a stack of factors that make certain sounds, words, and timing cues harder to decode—especially when the topic is technical or the pace is high. That’s why misunderstandings in meetings can happen even when everyone is fluent and prepared.
Common factors that stack up in real life:
- Accent variation + prosody + fast speech: Differences in rhythm, stress, and timing can change which syllables stand out, making words easier to miss at speed (especially “hard” words with unfamiliar stress patterns—see Hard English Words to Pronounce for foreigners).
- Channel issues: Background noise, weak microphones, audio compression, and unstable connections can blur consonants and reduce the cues listeners rely on.
- High-risk tokens: Proper nouns, acronyms, names, numbers, and domain jargon have low redundancy—if you miss one sound, you miss the meaning.
- Cognitive load in multilingual contexts: When listeners are already translating internally or tracking complex content, even small clarity gaps trigger breakdowns.
The result is predictable: repetition loops and listener fatigue for people who don’t want to interrupt, and missed details that show up later as wrong action items.
Why meetings amplify accent-related misunderstandings
If you’ve ever dealt with hard to understand accents on calls or online meetings, it’s rarely a single issue. Breakdowns usually come from a stack of factors that make certain sounds, words, and timing cues harder to decode—especially when the topic is technical or the pace is high.
Common factors that stack up in real life:
- Accent variation + prosody + fast speech: Differences in rhythm, stress, and timing can change which syllables stand out, making words easier to miss at speed (especially “hard” words with unfamiliar stress patterns—see Hard English Words to Pronounce for foreigners).
- Channel issues: Background noise, weak microphones, audio compression, and unstable connections can blur consonants and reduce the cues listeners rely on.
- High-risk tokens: Proper nouns, acronyms, names, numbers, and domain jargon have low redundancy—if you miss one sound, you miss the meaning.
- Cognitive load in multilingual contexts: When listeners are already translating internally or tracking complex content, even small clarity gaps can trigger breakdowns.
Meetings make these problems harder to recover from. They’re non-rewindable, so a misheard name, number, or decision point can’t be replayed in the moment—and because each statement depends on shared understanding of the last one, small mishears can compound quickly. Add fast turn-taking, overlap, and interruptions, and people often hesitate to ask again (“I don’t want to slow us down”), which pushes confusion underground until it surfaces later as misalignment.
Audio setups also vary widely across participants—headsets, laptop mics, mobile connections, different noise suppression—which widens intelligibility gaps and makes accented speech harder to catch under compression.
The result is predictable: repetition loops, listener fatigue, reduced participation from people who don’t want to interrupt, slower decisions, and lower confidence in action items because people aren’t fully sure what they heard.
How AI advances accelerated accent-related speech technology
Accent-focused speech tech became practical because the broader voice-AI ecosystem matured. At a high level, several shifts mattered:
- Better speech representations: Modern models learned richer, more stable audio features that capture pronunciation patterns more effectively than older hand-engineered approaches.
- Larger and more diverse datasets: Training data expanded across speakers, accents, devices, and acoustic conditions, improving generalization.
- Robustness to devices/noise/compression: Models improved at handling real-world audio artifacts that previously broke accent-sensitive systems.
- Faster inference: Optimization and hardware progress made low-latency processing feasible, enabling real-time voice conversion accent workflows.
Accent AI moved from offline experiments and post-processed demos to speech-to-speech accent conversion that can operate during live calls—where the value is highest, because that’s where misunderstandings actually disrupt work.
How real-time Accent AI technology works
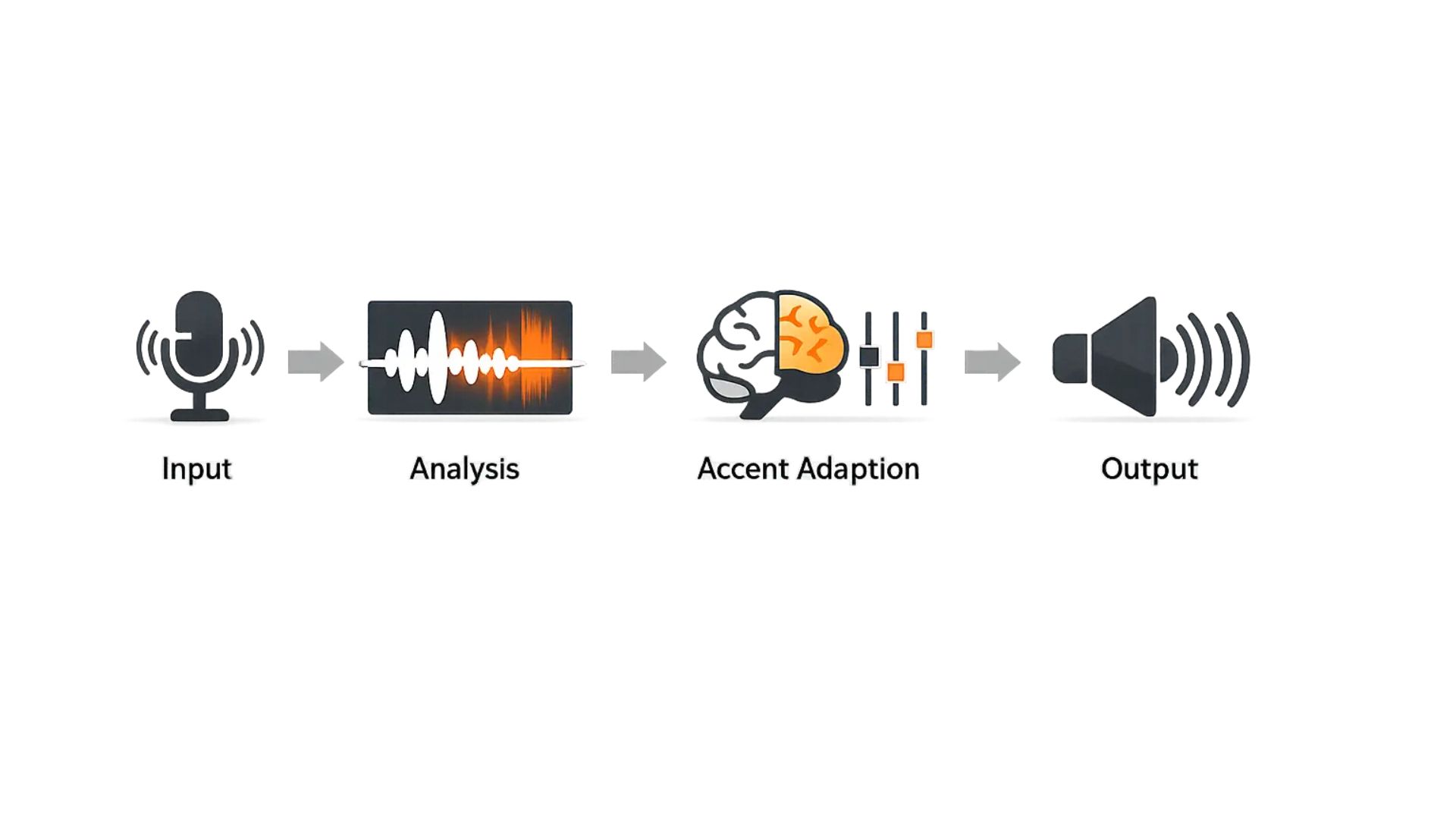
A simple real-time pipeline

Real-time Accent AI—also known as AI accent conversion for listeners—has one job: to improve understandability as you speak, without breaking the flow of conversation.
- In practical terms, the system follows a pipeline like this: it captures your microphone audio, then extracts speech features that represent pronunciation patterns. Next, a model decides what to adapt—typically small, targeted adjustments that make key sounds easier to distinguish.
- Finally, it outputs optimized speech in real time back into the call.
The hard constraint is latency. If processing adds noticeable delay, turn-taking gets awkward, people talk over each other, and the “fix” creates new communication problems. That’s why real-time solutions focus on low-latency inference and incremental processing, rather than heavy offline transformations.
Tradeoffs & limitations
Real-time Accent AI involves tradeoffs.
- Stronger adaptation can boost clarity but may sound less natural, while lighter changes preserve voice character.
- Proper nouns, acronyms, slang, and code-switching are common edge cases because context is limited.
- Latency also matters—high CPU load or poor network conditions can introduce delay or occasional artifacts.
- Privacy depends on implementation, but voice is sensitive data, so expect strong safeguards (user control and minimal retention).
The solution landscape: what products exist in Accent AI
Accent AI products fall into distinct categories, and each solves a different problem. Choosing the right one depends on whether you’re optimizing for learning, content creation, analytics, or real-time meeting clarity.
Category 1 — Accent measurement tools (identification/scoring/coaching)
These tools analyze speech to identify accent patterns or measure features like intelligibility markers, pronunciation consistency, or accent “strength.” They’re commonly used in learning workflows, coaching, call QA, and language training programs—where feedback and tracking matter more than live performance.
| Best for |
Not ideal for |
| learning and improvement programs, analytics, quality monitoring |
fixing real-time misunderstandings in meetings, because measurement alone doesn’t change what listeners hear in the moment. |
Category 2 — Accent generators (accented TTS & voice styling)
Accent generators produce speech with a selected accent or style, usually through text-to-speech or voice styling. They’re useful for narration, training content, localization, brand voice consistency, and simulations (e.g., role-play scenarios for support teams).
| Best for |
Not ideal for |
| content creation, training modules, localization and narration workflows |
live meeting comprehension or reducing “can you repeat that?” moments—unless explicitly built for real-time, interactive conversations. |
Category 3 — Real-time accent tools (communication-focused)
This category is built for live conversation. Instead of scoring or labeling accents, these systems act as an accent understanding tool by improving how clearly speech comes through during a call. Many rely on speech-to-speech accent conversion techniques that adapt specific pronunciation cues in real time, aiming to reduce the moments where listeners miss critical details.
- Best for: recurring meetings, customer demos, distributed teams, and any fast-paced discussion where clarity affects decisions.
- Symptoms addressed: frequent “can you repeat that?” loops, misheard names or numbers, repeated rephrasing, and meeting fatigue caused by constant repair and clarification.
The key distinction: the success metric isn’t “sounding native,” it’s fewer misunderstandings and smoother turn-taking without disrupting flow.
Krisp AI Accent Conversion for listeners—making accented speech easier to understand in real time

Krisp frames its approach as Listener-mode AI Accent Conversion (AI Accent Understanding): it helps listeners understand accented speech in real time during meetings—without asking speakers to change anything—so conversations don’t derail into “Sorry, can you repeat that?”
At a high level, Listener mode works this way: the speaker talks naturally; Krisp adapts accent-specific pronunciation patterns on the listener’s side in real time; the listener hears clearer speech—while the speaker’s authentic voice remains intact. This “inbound” approach is different from outbound accent conversion, where one person’s speech is altered for everyone else.
Krisp also offers Speaker-mode (outbound) AI Accent Conversion. In this mode, the speaker keeps talking naturally, but Krisp improves how that speaker is understood by everyone on the call—so the whole room benefits, not just a single listener.
Krisp emphasizes deployment practicality: these modes run fully on-device (CPU-only) with near real-time latency (≤200ms), and work across major conferencing platforms (Zoom, Microsoft Teams, Google Meet, Webex, Slack) through Krisp’s virtual audio layer with zero integrations. On privacy, Krisp says it doesn’t train models on user data and that audio is processed in real time and not stored.
The result: fewer interruptions for clarification, smoother back-and-forth, and more confidence that key details—names, numbers, and action items—land correctly, especially in global team meetings, customer calls, and fast-moving decisions.
Ethics and trust: using Accent AI respectfully
People ask “is accent modification ethical” because accents are identity, not a flaw. The defensible workplace frame is clarity and inclusion, not conformity. Policies should also acknowledge that accent is tightly linked to protected characteristics in employment contexts; the EEOC explicitly includes discrimination because of “ethnicity or accent” under national origin discrimination.
Principles that reduce ethical and legal risk:
- User choice and control: the individual decides when to use it.
- No coercion: don’t make it a condition of participation, performance ratings, or promotion.
- Transparency where appropriate: if teams standardize on tools, explain the intent (fewer repeats, better comprehension) in non-stigmatizing terms.
- Measure outcomes, not “accent removal”: repeats, comprehension, speed, action-item accuracy—not “sounding native.”
Risks to call out directly: tools can reinforce accent discrimination at work if they’re framed as “fixing people,” and they can become gatekeeping in hiring (accent bias hiring) if organizations treat accent as a proxy for competence. U.S. labor guidance also notes that disparate treatment because of accent and exclusion based on customer preference can be discriminatory.
Conclusion
Accent AI is about reducing friction in conversations. When deployed for real-time understandability, it can cut repeat loops, prevent misheard names or numbers, and make meetings move faster with better inclusion.
The right approach depends on your goal—measurement, generation, or live clarity—but the best results come from focusing on outcomes: comprehension, confidence, and cleaner decisions.
FAQs
What is Accent AI?
Accent AI covers techniques that model accent variation to analyze speech, generate speech in a chosen accent or style, or improve how understandable speech is—especially in real-time communication.
What’s the difference between accent measurement, accent generators, and real-time understandability tools?
Measurement tools classify or score accent features for coaching and analytics. Generators create speech in a selected accent or style (usually via text-to-speech). Real-time understandability tools improve intelligibility during live calls to reduce repeats and mishears.
Can Accent AI help in real-time meetings?
Yes—if it’s built for real-time use. Communication-focused systems aim to reduce “can you repeat that?” loops by improving intelligibility during live conversation, where misunderstandings are most disruptive.
Will Accent AI change what I’m saying?
It shouldn’t change meaning or content. Communication-focused Accent AI targets how speech is perceived (clarity cues), not the words you choose. That said, any real-time processing can introduce occasional artifacts.
What are the limitations of real-time accent technology?
Tradeoffs include naturalness versus strength of change, edge cases like proper nouns, slang, and code-switching, latency constraints, and the possibility of audio artifacts—especially in poor network or noisy conditions.
Is it ethical to use Accent AI at work?
Yes—when it’s opt-in and designed to support clearer communication, not to “fix” people. Best practices include avoiding coercion, being transparent where appropriate, and focusing on outcomes like fewer repeat requests and better understanding.